|
|
### [$CSP-J$ $2022$] 上升点列
|
|
|
[P8816 [CSP-J 2022] 上升点列(民间数据)](https://www.luogu.com.cn/problem/P8816)
|
|
|
|
|
|
[前导知识练习 力扣 664. 奇怪的打印机](https://www.cnblogs.com/littlehb/p/16869777.html)
|
|
|
|
|
|
|
|
|
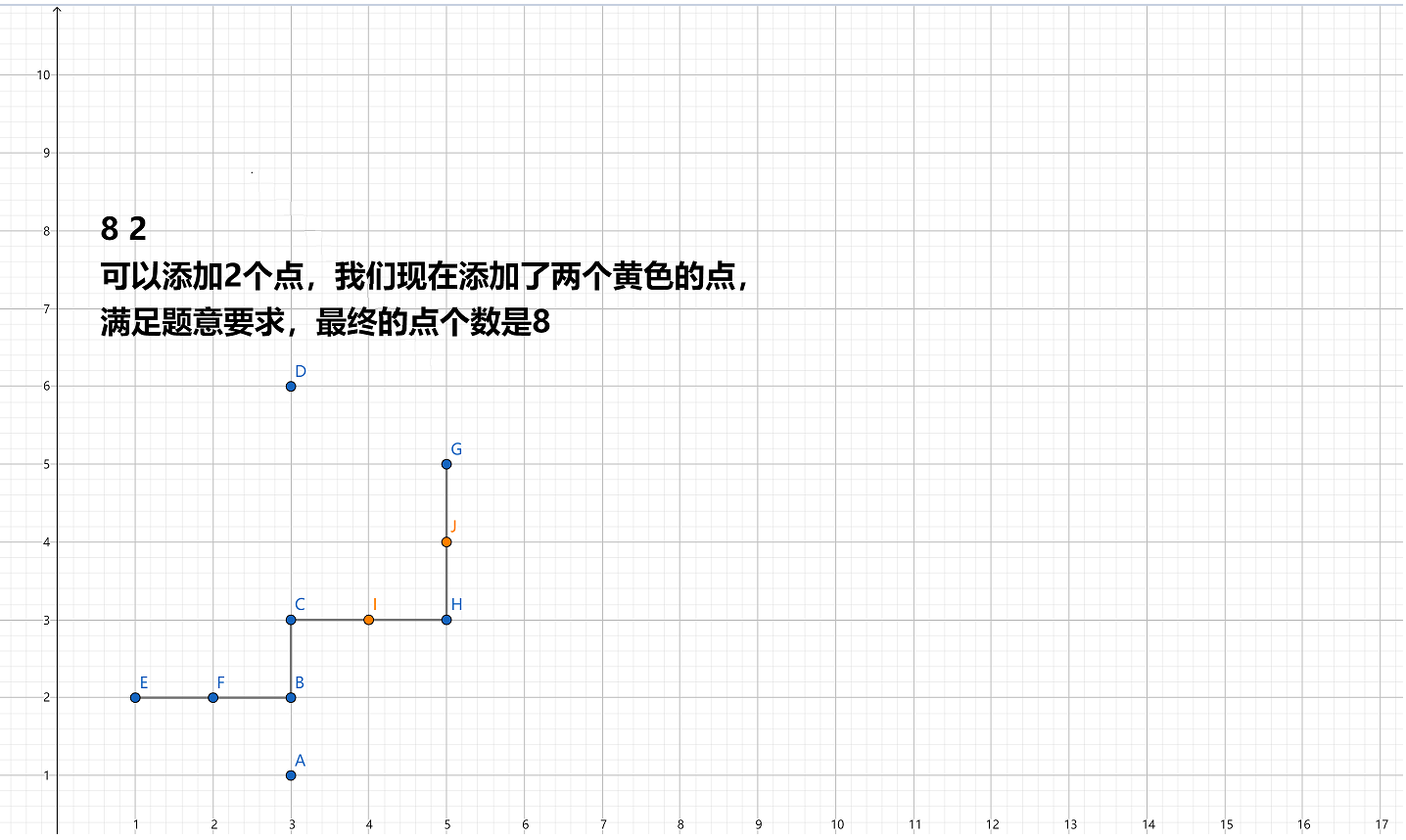
样例$1$输入解析
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 动态规划解法
|
|
|
|
|
|
这种题目乍一看就能想到是 **$dp$** 或者 **二分**,从哪个先开始考虑都没问题
|
|
|
|
|
|
思考二分最后会发现不知道该从何入手,如果是二分长度,那不知道起点,二分起点,那也没有意义
|
|
|
|
|
|
再配合数据范围只有$500$,这种数据范围大概率就是$dp$,那么来思考$dp$
|
|
|
|
|
|
#### 状态表示
|
|
|
很容易想到$f[i][j]$表示到第$i$个节点,已经用掉了$j$个可添加点的 **最大长度**
|
|
|
|
|
|
#### 状态转移
|
|
|
状态有了,转移应该也很容易想到,对于第$i$个节点,无非就是枚举其他节点$j$,如果$j$在$i$的左下方即可进行转移,计算
|
|
|
$$\large d=a[i].x-a[j].x+a[i].y-a[j].y-1$$
|
|
|
即$j$到$i$ 需要使用 $d$ 个可添加点
|
|
|
|
|
|
现在的场景是从$j->i$,对于状态表示$f[i][?]$的一维已经确定是从$f[j][?]->f[i][??]$了,这两个问题间的转移是关键问题了:
|
|
|
|
|
|
那么枚举$f[j][k]$,即可得到方程
|
|
|
$$\large f[i][k+d]=max(f[j][k]+d+1)$$
|
|
|
|
|
|
最后答案即为
|
|
|
$$\large ans = max(ans, f[i][k + d] + m - k - d)$$
|
|
|
|
|
|
#### 注意
|
|
|
这里注意一个小细节,如果总共有 $m$ 个可添加点,只用了$k+d$个,多出来的$m-k-d$个直接加在最后即可,不要忘记这个,不过这个坑在第二组$sample$里就给出来了,基本不会有人踩
|
|
|
|
|
|
<font color='red' size=4><b>不把测试用例看完,画出来,理解掉的人是傻子!!!</b></font>
|
|
|
|
|
|
检查一下复杂度,是$O(n^2K)$,显然没有问题
|
|
|
```cpp {.line-numbers}
|
|
|
#include <bits/stdc++.h>
|
|
|
using namespace std;
|
|
|
const int N = 510;
|
|
|
const int M = 110;
|
|
|
struct Node {
|
|
|
int x, y;
|
|
|
/*
|
|
|
Q1:为什么要排序?
|
|
|
A:因为要DP,需要解决无后效性。也就是有一定的单调性,从左向右,从上向下填表,填完的数值不能再被修改,需要有一定的依赖关系顺序
|
|
|
|
|
|
Q2:按什么来排序?
|
|
|
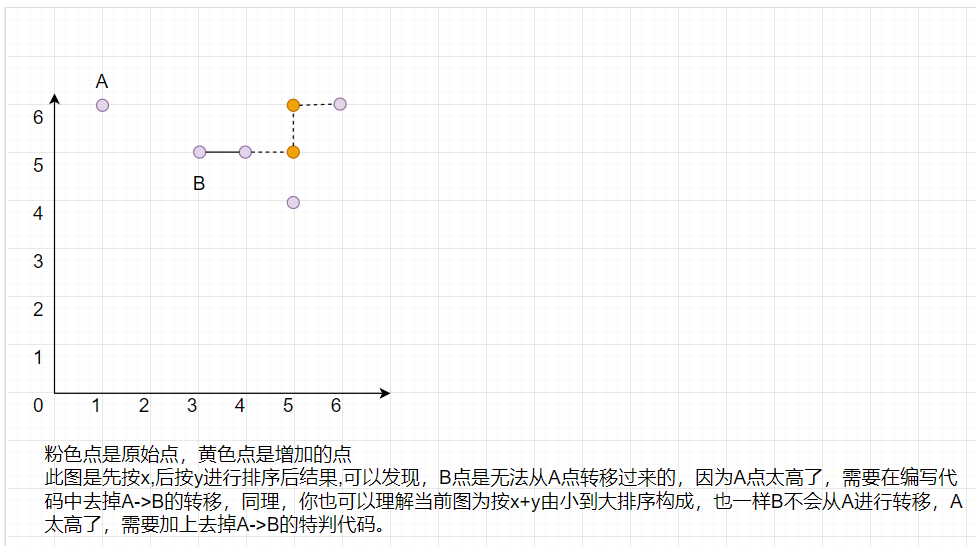
A:可以按x+y来排序,也可以按先x,后y的方式来排序,都是一样的。
|
|
|
|
|
|
1.按x+y排序
|
|
|
const bool operator<(const Node &t) {
|
|
|
return x + y < t.x + t.y;
|
|
|
}
|
|
|
*/
|
|
|
// 2.先按x,再按y排序
|
|
|
const bool operator<(const Node &t) {
|
|
|
if (x == t.x) return y < t.y;
|
|
|
return x < t.x;
|
|
|
}
|
|
|
} a[N];
|
|
|
|
|
|
int f[N][M];
|
|
|
int ans;
|
|
|
|
|
|
int main() {
|
|
|
//文件输入
|
|
|
// freopen("point.in", "r", stdin);
|
|
|
|
|
|
int n, m;
|
|
|
cin >> n >> m;
|
|
|
|
|
|
for (int i = 1; i <= n; ++i) cin >> a[i].x >> a[i].y;
|
|
|
sort(a + 1, a + 1 + n);
|
|
|
|
|
|
// dp初始化,最后一个点是以i号点选中,并且,使用了j个虚拟点情况下,获得的最长序列长度
|
|
|
for (int i = 1; i <= n; i++)
|
|
|
for (int j = 0; j <= m; j++)
|
|
|
f[i][j] = j + 1; //以i点结束,并且,使用了j个虚拟点,最起码可以构成一个最长长度为j+1的序列
|
|
|
|
|
|
//状态转移
|
|
|
for (int i = 1; i <= n; i++) //枚举每个原始点
|
|
|
for (int j = 1; j < i; j++) { //枚举每个前序点
|
|
|
if (a[i].x < a[j].x || a[i].y < a[j].y) continue; //如果j不在i的左下方,无效转移
|
|
|
int d = a[i].x - a[j].x + a[i].y - a[j].y - 1; // j->i 需要增加的虚拟点个数
|
|
|
|
|
|
/*
|
|
|
讨论j点的哪些子状态 可以转移到 i的哪些子状态?
|
|
|
思考一下f[j]的二维状态,最小值是0,最大值是m
|
|
|
现在f[j]的二维状态变化量是固定的,是d
|
|
|
所以需要枚举j的所有以转移的二维状态值:0 ~ m-d
|
|
|
*/
|
|
|
for (int k = 0; k <= m - d; k++) {
|
|
|
// f[j][k]是前序状态,可以通过+d转移到新的状态
|
|
|
// f[j][k+d]+d+1 -> f[i][k+d]
|
|
|
f[i][k + d] = max(f[i][k + d], f[j][k] + d + 1);
|
|
|
|
|
|
//在状态转移完成后,收集一下答案
|
|
|
//小坑一个:给你m个虚拟点,你最后没用了的话,就是浪费,因为最起码,
|
|
|
//把多出来的放在最后就可以增长序列长度
|
|
|
ans = max(ans, f[i][k + d] + m - k - d); //更新序列最长长度
|
|
|
}
|
|
|
}
|
|
|
|
|
|
//输出结果
|
|
|
printf("%d\n", ans);
|
|
|
return 0;
|
|
|
}
|
|
|
```
|
|
|
|
|
|
[最优子结构及 $dp$ 数组遍历方向的问题](https://zhuanlan.zhihu.com/p/100993613)
|
|
|
|
|
|
* $1$、遍历的过程中,所需的状态必须是已经计算出来的
|
|
|
* $2$、遍历的终点必须是存储结果的那个位置
|
|
|
|
|
|
#### 记忆化搜索解法I
|
|
|
```c++
|
|
|
#include <bits/stdc++.h>
|
|
|
const int N = 510;
|
|
|
|
|
|
//性能:第12号测试点,时间最长,65ms
|
|
|
|
|
|
/*
|
|
|
搜索代码:暴力枚举每次选择哪个点,能选就选,维护剩下几个自由点,加个记忆化即可通过
|
|
|
*/
|
|
|
using namespace std;
|
|
|
int n, m, ans;
|
|
|
int x[N], y[N]; //对于二维坐标,两个x,y数组,明显比使用struct的结构体数组方便,但是,不利用整体排序
|
|
|
int f[N][N]; //结果数组
|
|
|
|
|
|
//从u点出发,还有r个虚拟点可用,可以获得的最长序列长度是多少
|
|
|
int dfs(int u, int r) {
|
|
|
if (~f[u][r]) return f[u][r]; //计算过则直接返回
|
|
|
int ans = r + 1; //剩余r个虚拟点,再加上当前点u,最起码能有r+1点的序列长度
|
|
|
|
|
|
for (int i = 1; i <= n; i++) { //谁能做为我的后续点
|
|
|
if (u == i) continue; //自己不能做为自己的直接后续点
|
|
|
if (x[i] < x[u] || y[i] < y[u]) continue; //排除掉肯定不可能成为我后续点的点
|
|
|
int d = x[i] - x[u] + y[i] - y[u] - 1; // u->i之间缺少 多少个虚拟点
|
|
|
if (d > r) continue; //如果需要的虚拟点个数大于剩余的虚拟点个数,那么i 无法做为u的后续点
|
|
|
ans = max(ans, dfs(i, r - d) + d + 1); //在消耗了d个虚拟点之后,成功到达了i这个点;
|
|
|
//①已经取得的序列长度贡献u和d个虚拟点,共d+1个
|
|
|
//②问题转化为求未知部分:以i点为出发点,剩余虚拟点个数r-d个的情况下可以获取到的最长序列长度
|
|
|
}
|
|
|
return f[u][r] = ans; //记忆化
|
|
|
}
|
|
|
|
|
|
int main() {
|
|
|
//文件输入
|
|
|
// freopen("point.in", "r", stdin);
|
|
|
memset(f, -1, sizeof f);
|
|
|
|
|
|
cin >> n >> m;
|
|
|
for (int i = 1; i <= n; i++) cin >> x[i] >> y[i];
|
|
|
|
|
|
for (int i = 1; i <= n; i++) ans = max(ans, dfs(i, m));
|
|
|
printf("%d\n", ans);
|
|
|
return 0;
|
|
|
}
|
|
|
```
|
|
|
|
|
|
#### 记忆化搜索优化版本
|
|
|
```c++
|
|
|
#include <bits/stdc++.h>
|
|
|
const int N = 510;
|
|
|
|
|
|
//性能:第12号测试点,时间最长,22ms
|
|
|
/*
|
|
|
搜索代码:暴力枚举每次选择哪个点,能选就选,维护剩下几个自由点,加个记忆化即可通过
|
|
|
*/
|
|
|
using namespace std;
|
|
|
int n, m, ans;
|
|
|
|
|
|
int f[N][N]; //结果数组
|
|
|
struct Node {
|
|
|
int x, y;
|
|
|
const bool operator<(Node &t) const {
|
|
|
if (x == t.x) return y < t.y;
|
|
|
return x < t.x;
|
|
|
}
|
|
|
} a[N];
|
|
|
|
|
|
//从u点出发,还有r个虚拟点可用,可以获得的最长序列长度是多少
|
|
|
int dfs(int u, int r) {
|
|
|
if (~f[u][r]) return f[u][r]; //计算过则直接返回
|
|
|
int ans = r + 1; //剩余r个虚拟点,再加上当前点u,最起码能有r+1点的序列长度
|
|
|
|
|
|
for (int i = u + 1; i <= n; i++) { //谁能做为我的后续点
|
|
|
if (u == i) continue; //自己不能做为自己的直接后续点
|
|
|
if (a[i].x < a[u].x || a[i].y < a[u].y) continue; //排除掉肯定不可能成为我后续点的点
|
|
|
int d = a[i].x - a[u].x + a[i].y - a[u].y - 1; // u->i之间缺少 多少个虚拟点
|
|
|
if (d > r) continue; //如果需要的虚拟点个数大于剩余的虚拟点个数,那么i 无法做为u的后续点
|
|
|
ans = max(ans, dfs(i, r - d) + d + 1); //在消耗了d个虚拟点之后,成功到达了i这个点;
|
|
|
//①已经取得的序列长度贡献u和d个虚拟点,共d+1个
|
|
|
//②问题转化为求未知部分:以i点为出发点,剩余虚拟点个数r-d个的情况下可以获取到的最长序列长度
|
|
|
}
|
|
|
return f[u][r] = ans; //记忆化
|
|
|
}
|
|
|
|
|
|
int main() {
|
|
|
//文件输入
|
|
|
// freopen("point.in", "r", stdin);
|
|
|
|
|
|
memset(f, -1, sizeof f);
|
|
|
|
|
|
cin >> n >> m;
|
|
|
for (int i = 1; i <= n; i++) cin >> a[i].x >> a[i].y;
|
|
|
sort(a + 1, a + 1 + n);
|
|
|
|
|
|
for (int i = 1; i <= n; i++) ans = max(ans, dfs(i, m));
|
|
|
printf("%d\n", ans);
|
|
|
return 0;
|
|
|
}
|
|
|
``` |