60 KiB
【前导知识】
换根DP
换根DP,又叫二次扫描,是树形DP的一种。
其相比于一般的树形DP具有以下特点:
- ① 以树上的不同点作为根,其解不同
- ② 故为求解答案,不能单求某点的信息,需要求解每个节点的信息
- ③ 故无法通过一次搜索完成答案的求解,因为一次搜索只能得到一个节点的答案
难度也就要比一般的树形
DP高一点。
题单
P3478 STA-Station
题意:给定一个
n个点的无根树,问以树上哪个节点为根时,其所有节点的深度和最大? 深度:节点到根的简单路径上边的数量 关键词:换根DP模板题
如果我们假设某个节点为根,将无根树化为有根树,在搜索回溯时统计子树的深度和,则可以用一次搜索算出以该节点为根时的深度和,其时间复杂度为 O(N)。
但这样求解出的答案只是以该节点为根的,并不是最优解。
如果要暴力求解出最优解,则我们可以枚举所有的节点为根,然后分别跑一次搜索,这样的时间复杂度会达到O(N^2),显然不可接受。
所以我们考虑在第二次搜索时就完成所有节点答案的统计——
-
① 我们假设第一次搜索时的根节点为
1号节点,则此时只有1号节点的答案是已知的。同时第一次搜索可以统计出所有子树的大小。 -
② 第二次搜索依旧从
1号节点出发,若1号节点与节点x相连,则我们考虑能否通过1号节点的答案去推出节点x的答案。 -
③ 我们假设此时将根节点换成节点
x,则其子树由两部分构成,第一部分是其原子树,第二部分则是1号节点的其他子树(如下图)。
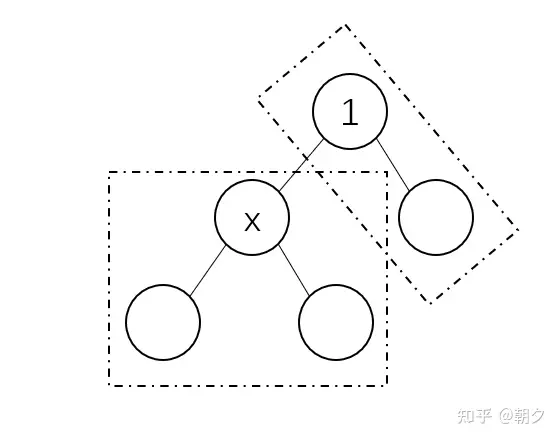
- ④ 根从
1号节点变为节点x的过程中,我们可以发现第一部分的深度降低了1,第二部分的深度则上升了1,而这两部分节点的数量在第一次搜索时就得到了。
故得到递推公式:
f[v]=f[u]-sz[v]+(sz[1]-sz[v]),fa[v]=u简化一下就是
f[v]=f[u]+sz[1]-2\times sz[v]=f[u]+n-2\times sz[v]#include <bits/stdc++.h>
using namespace std;
const int N = 1000010, M = N << 1;
#define int long long
#define endl "\n"
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int n; // n个节点
int depth[N]; // depth[i]:在以1号节点为根的树中,i号节点的深度是多少
int sz[N]; // sz[i]:以i号节点为根的子树中有多少个节点
int f[N]; // DP结果数组,f[i]记录整个树以i为根时,可以获取到的深度和是多少
// 第一次dfs
void dfs1(int u, int fa) {
sz[u] = 1; // 以u为根的子树,最起码有u一个节点
depth[u] = depth[fa] + 1; // u节点的深度是它父节点深度+1
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u); // 深搜v节点,填充 sz[v],depth[v]
sz[u] += sz[v]; // 在完成了sz[v]和depth[v]的填充工作后,利用儿子更新父亲的sz[u]+=sz[v];
}
}
// 第二次dfs
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
f[v] = f[u] + n - 2 * sz[v];
dfs2(v, u);
}
}
signed main() {
memset(h, -1, sizeof h); // 初始化链式前向星
cin >> n;
for (int i = 1; i < n; i++) { // n-1条边
int a, b;
cin >> a >> b;
add(a, b), add(b, a); // 换根DP,无向图
}
// 1、第一次dfs,以1号节点为根,它的父节点不存在,传入0
dfs1(1, 0);
// 2、换根
for (int i = 1; i <= n; i++) f[1] += depth[i]; // DP初始化,以1号节点为根时,所有节点的深度和
dfs2(1, 0); // 从1号节点开始,深度进行换根
// 3、找答案
int ans = 0, id = 0;
for (int i = 1; i <= n; i++) // 遍历每个节点
if (ans < f[i]) ans = f[i], id = i; // ans记录最大的深度值,id记录以哪个节点为根时取得最大值
// 输出以哪个节点为根时,深度和最大
cout << id << endl;
}
总结与进阶
由此我们可以看出换根DP的套路:
- 指定某个节点为根节点。
- 第一次搜索完成预处理(如子树大小等),同时得到该节点的解。
- 第二次搜索进行换根的动态规划,由已知解的节点推出相连节点的解。
P1364 医院设置
一、O(N^3)算法
#include <bits/stdc++.h>
using namespace std;
const int N = 1000010;
const int INF = 0x3f3f3f3f;
int g[150][150];
int w[N];
int main() {
int n;
cin >> n;
// 地图初始化
memset(g, 0x3f, sizeof g);
for (int i = 1; i <= n; i++) g[i][i] = 0;
for (int i = 1; i <= n; i++) {
int a, b;
cin >> w[i] >> a >> b;
g[i][a] = g[a][i] = 1; // 左链接,右链接,二叉树,和一般的不一样
g[i][b] = g[b][i] = 1;
}
// floyd
for (int k = 1; k <= n; k++)
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
if (g[i][j] > g[i][k] + g[k][j]) g[i][j] = g[i][k] + g[k][j];
int ans = INF;
for (int i = 1; i <= n; i++) {
int s = 0;
for (int j = 1; j <= n; j++) s += w[j] * g[i][j];
ans = min(ans, s);
}
printf("%d", ans);
return 0;
}
二、O(N^2)算法
n 的值很小,最多可以有 O(n^3) 的时间复杂度。
那么就可以枚举每一个节点,计算它的 最小距离和 ,再统计答案。
最小距离和 怎么计算呢?容易想到的是枚举所有节点,算出两个节点之间的距离,再乘上这个节点的价值。
这样就需要求出节点之间的距离。先枚举起点,然后算出每个节点到这个起点间的距离。我用的是一个朴素的 dfs,在搜索的过程中累加距离,每搜索到一个节点,就储存这个节点与起点间的距离。
而累加距离也很容易实现,在从一个节点遍历到下一个节点时,step 增加 1;
代码就很好实现了,时间复杂度也不高,O(n^2)。
#include <bits/stdc++.h>
using namespace std;
const int N = 110, M = N << 1;
const int INF = 0x3f3f3f3f;
int n;
int x[N]; // 点权权值数组
int st[N]; // st 数组存是否遍历过这个节点
int dis[N][N]; // 存节点间的距离
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
void dfs(int root, int u, int step) { // root 表示根,u:当前走到哪个节点,step:到u点时走了几步
st[u] = 1; // u走过了,防止回头路
dis[root][u] = step, dis[u][root] = step; // root<->u之间的路径长度
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (st[v]) continue;
dfs(root, v, step + 1);
}
}
int main() {
// 初始化链式前向星
memset(h, -1, sizeof h);
cin >> n;
for (int i = 1; i <= n; i++) {
int a, b;
cin >> x[i] >> a >> b;
if (a) add(i, a), add(a, i); // 存图
if (b) add(i, b), add(b, i);
}
for (int i = 1; i <= n; i++) {
memset(st, 0, sizeof st);
dfs(i, i, 0); // 搜索
}
int ans = INF;
for (int i = 1; i <= n; i++) {
int s = 0;
for (int j = 1; j <= n; j++)
s = s + x[j] * dis[i][j]; // 累加距离
ans = min(ans, s);
}
cout << ans << endl;
return 0;
}
三、O(N)算法
如果n=1e6,那么就要考虑换根dp了
我们考虑相邻的医院是否存在转换关系,设其中一个医院为u(父节点),另一个为v(子节点)
如果把u点的医院改为v点,则发现:
如图:以5为根时:
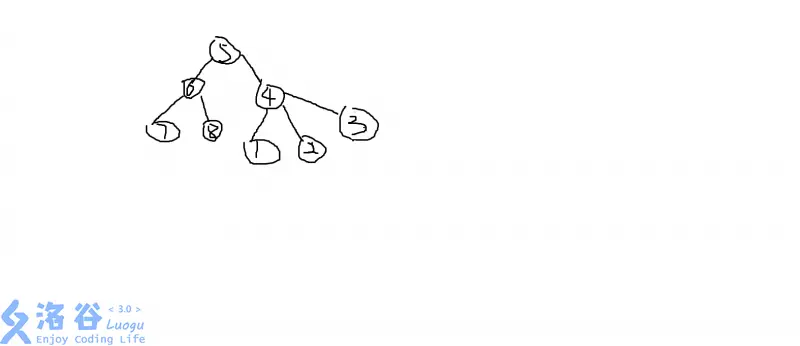
以4为根时:

以v为根的子树的集合的所有人少走1步,但是另一集合的所有人要多走一步
设sz[i]表示以i为根节点的集合人的总数,f[i]表示在i点设置医院的代价,则可转换成:
\large f[v]=f[u]+(sz[1]-sz[v])-sz[v]=f[u]+sz[1]-2\times sz[v]注: 其中
sz[1]表示全部人的数量,一般也写做n
思路:
先算出1个点的代价,之后dp换根直接转换
Code
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10, M = N << 1;
const int INF = 0x3f3f3f3f;
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int c[N];
int f[N], sz[N];
int ans = INF;
// 第一次dfs,获取在以1为根的树中:
// 1、每个节点分别有多少个子节点,填充sz[]数组
// 2、获取到f[1],f[1]表示在1点设置医院的代价
// 获取到上面这一组+一个数据,才能进行dfs2进行换根
void dfs1(int u, int fa, int step) {
sz[u] = c[u]; // 这个挺绝啊~,与一般的统计子树节点个数不同,这里把人数,也就是点权值,也看做是一个节子点,想想也是这个道理
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u, step + 1); // 填充深搜v节点为根的子树
sz[u] += sz[v]; // 在完成了v节点的数据统计后,用v节点的sz[v]结果累加到sz[u]
}
f[1] += step * c[u]; // 累加步数*人数 = 1点的总代价,预处理出1点的总代价
}
// 第二次dfs,开始dp换根
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
f[v] = f[u] + sz[1] - sz[v] * 2; // 经典的递推式
dfs2(v, u); // 继续深搜
}
}
int main() {
// 初始化链式前向星
memset(h, -1, sizeof h);
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> c[i];
int a, b;
cin >> a >> b;
if (a) add(a, i), add(i, a); // 是一个二叉树结构,与左右节点相链接,但有可能不存在左或右节点,不存在时,a或b为0
if (b) add(b, i), add(i, b);
}
// 1、准备动作
dfs1(1, 0, 0);
// 2、换根dp
dfs2(1, 0);
// 输出答案
for (int i = 1; i <= n; i++) ans = min(ans, f[i]);
cout << ans << endl;
return 0;
}
P2986 伟大的奶牛聚集
题目描述
Bessie 正在计划一年一度的奶牛大集会,来自全国各地的奶牛将来参加这一次集会。当然,她会选择最方便的地点来举办这次集会。
每个奶牛居住在 N 个农场中的一个,这些农场由 N-1 条道路连接,并且从任意一个农场都能够到达另外一个农场。道路 i 连接农场 A_i 和 B_i,长度为 L_i。集会可以在 N 个农场中的任意一个举行。另外,每个牛棚中居住着 C_i 只奶牛。
在选择集会的地点的时候,Bessie 希望最大化方便的程度(也就是最小化不方便程度)。比如选择第 X 个农场作为集会地点,它的不方便程度是其它牛棚中每只奶牛去参加集会所走的路程之和(比如,农场 i 到达农场 X 的距离是 20,那么总路程就是 C_i\times 20)。帮助 Bessie 找出最方便的地点来举行大集会。
题目分析 这还分析个啥啊,这不就是上一道题的医院选址吗?
Code
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10, M = N << 1;
#define int long long
#define endl "\n"
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int c[N]; // 点权数组
int sz[N]; // sz[i]:在以1号节点为根时,i号节点的子节点数量
int dis[N]; // dis[i]:表示i距离起点的长度
int f[N]; // f[i]:把奶牛大集会的地点设为i时的最小代价
int ans = 1e18;
// 第一次dfs,获取在以1为根的树中:
// 1、每个节点分别有多少个子节点,填充sz[]数组
// 2、获取到f[1],f[1]表示在1点设置医院的代价
// 获取到上面这一组+一个数据,才能进行dfs2进行换根
void dfs1(int u, int fa) {
sz[u] = c[u]; // 这个和医院选址是一样的,点权就是子节点个数
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dis[v] = dis[u] + w[i]; // 每个点到根节点的距离,这个和医院选址是不一样的,那个是一步+1,用step记录即可,这个还有边权
dfs1(v, u); // 深搜
sz[u] += sz[v]; // 以u为根的子树奶牛数量
}
f[1] += dis[u] * c[u]; // 累加 距离*人数=1点的总代价
}
// 第二次dfs,开始dp换根
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
f[v] = f[u] + (sz[1] - sz[v] * 2) * w[i];
dfs2(v, u);
}
}
signed main() {
// 初始化链式前向星
memset(h, -1, sizeof h);
int n;
cin >> n;
for (int i = 1; i <= n; i++) cin >> c[i];
for (int i = 1; i < n; i++) {
int a, b, c;
cin >> a >> b >> c;
add(a, b, c), add(b, a, c);
}
// 1、准备动作
dfs1(1, 0);
// 2、换根dp
dfs2(1, 0);
// 输出答案
for (int i = 1; i <= n; i++) ans = min(ans, f[i]);
cout << ans << endl;
}
CF1187E Tree Painting
题意
给定一棵有 n 个结点的无根树,所有结点都是白色的。
第一次操作可以 随意 使一个结点染成黑色,之后每次操作可以使一个与黑色结点相邻的白色结点变成黑色。
每次操作可以获得的权值为: 被染成黑色的白色结点所在的白色连通块的结点数量。
求可以获得的最大权值。
难点解析
最初时,我对这个权值 的认识不够深入,没有明白为什么根不同权值就会不同呢?后来仔细思考,发现是自己傻了,因为根不同,每个节点到根的距离就会不同,而权值的计算办法,其实是类似于哈夫曼树,父子隶属关系的不同最终的权值是不一样的,我们可以再画一下上面的图进行深入理解:
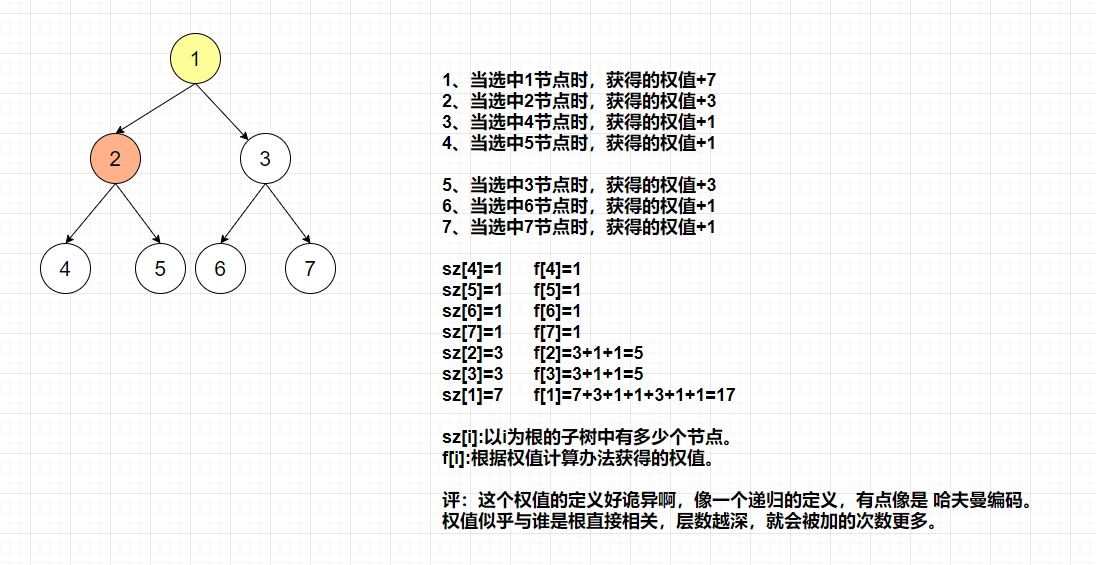
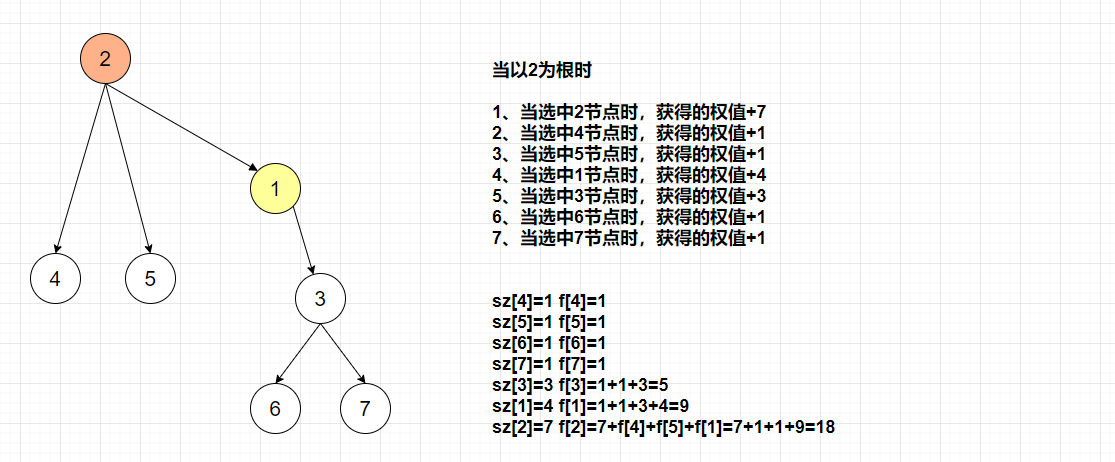
总结:题目理解能力,目前看来有两种办法:
- ① 多动手画图理解,尝试换根试一下。
- ② 多做题,做的多了就一下明白它说什么了。
题解 不难发现只要选定了第一个被染色的结点,答案也就确定了, 也就是 选了谁是根最重要,其它的选择顺序不重要。
所以有一个朴素做法就是以枚举每个结点为根,都做一次树形dp。
以某一结点为根,记 f[i] 表示以 i 为根的子树中,首先把 i 染成黑色的权值。
状态转移方程:
\displaystyle \large f[u]=sz[u]+\sum_{v \in son[u]} f[v]
其中
sz[u] 表示以 u 为根的子树大小,也就是染色时的白色连通块大小。
时间复杂度
O(n^2) ,稳稳地暴毙,然后就会自然而然地想到换根dp。
换根dp
先考虑以1号点为根,求出 f 数组。
然后记 g[i] 表示以 i 结点为根时的答案,尝试通过1号节点的计算已知值,进行换根,利用数学变换加快运算速度。
显然,由于1号节点是根,它没有向上走的路径,所以它的向下所有获取的价值就是总价值,也就是 g[1] =f[1]
然后考虑 g 数组从 父亲到儿子 的转移。
以样例为例:
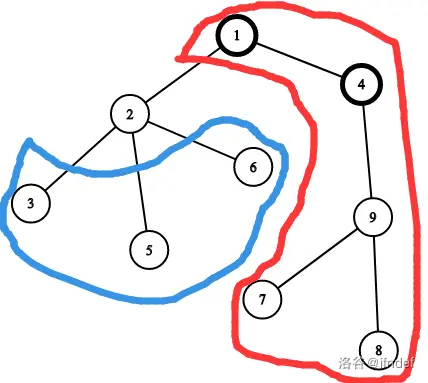
我们假设当前以 1 号为根,求出了 f 数组,也就是知道了 g[1]=f[1] ,然后要求出 g[2] 。
考虑一下答案的组成。
首先考虑 2 号结点的孩子的贡献,也就是图中蓝圈内的部分。这部分显然不会改变,贡献就是 f[2] −sz[2] 。
然后考虑父亲方向,也就是图中红圈部分对 g[2] 的贡献。
那么除了以 2 号结点,与 1 号结点相邻的其他子树都会对答案产生贡献,也就是说,我们只需要用以 1 号结点为根时的权值减去以 2 为根的子树的贡献即可,也就是 g[1]-sz[2]-f[2] 。
综合一下上述两种方向的贡献,可以得到:
g[2]=n+(f[2]-sz[2])+(g[1]-f[2]-sz[2])=n+g[1]-sz[2]\times 2推广到所有节点,就可以得到:
g[v]=n+g[u]-sz[v]\times 2然后跑两遍 dfs 就愉快的解决啦。
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl "\n"
const int N = 200010, M = N << 1;
int n;
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int sz[N]; // sz[i]:以i为根的子树中有多少个节点
int f[N];
int g[N];
int ans; // 答案
// 以子填父
void dfs1(int u, int fa) {
sz[u] = 1; // 以u为根的子树,最起码有u自己1个节点
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u); // 换根dp的套路,第一次 dfs,以子填父,先递归,后累加
sz[u] += sz[v]; // 将儿子节点v子树的节点数量,累加到u子树上
f[u] += f[v]; // 权值也需要累加
}
f[u] += sz[u]; // 别忘了加上自己子树的个数,之所以放在这里写,是因为需要所有子树递归完成统计后才有sz[u]
}
// 换根dp
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue; // 填充g[]数组的权值最大值
// 此处 sz[1]=n,怎么写都行
g[v] = n + g[u] - 2 * sz[v]; // 数学方法计算出来,修改v的最终答案
// 自顶向下修改统计信息,统计信息是指以每个点为根时可以获取到的最大权值
dfs2(v, u);
}
}
signed main() {
// 初始化链式前向星
memset(h, -1, sizeof h);
cin >> n;
for (int i = 1; i < n; i++) {
int a, b;
cin >> a >> b;
add(a, b), add(b, a);
}
// 第一次dfs,以子孙节点信息更新父节点的统计信息,统计信息包括:以u为根的子树中节点数个sz[u],每个节点可以获取到的权值f[u]
dfs1(1, 0);
// f[i]:以1为根时的, 以i为子树根的子树可以获得的最大权值
// g[i]:以i为根的子树可以获得的最大权值,也就是最终的结果存储数组
g[1] = f[1];
// 第二次dfs,换根
dfs2(1, 0);
// 遍历一遍历,找出到底以谁为根可以获取到权值的最大值,最大值是多少
for (int i = 1; i <= n; i++) ans = max(ans, g[i]);
// 输出答案
cout << ans << endl;
}
CF1324F.Maximum White Subtree
题目大意
- 给定一棵
n个节点无根树,每个节点u有一个颜色a_u,若a_u为0则u是黑点,若a_u为1则u是白点。 - 对于每个节点
u,选出一个包含u的连通子图,设子图中白点个数为cnt_1,黑点个数为cnt_2,请最大化cnt_1 - cnt_2。并输出这个值。 1 \leq n \leq 2 \times 10^5,0 \leq a_u \leq 1。
思路分析
这题要求的是求出对任何一个节点v,求出包含这个节点的子树cnt_1−cnt_2的最大值。
暴力想法
首先思考下暴力写法应该如何写。
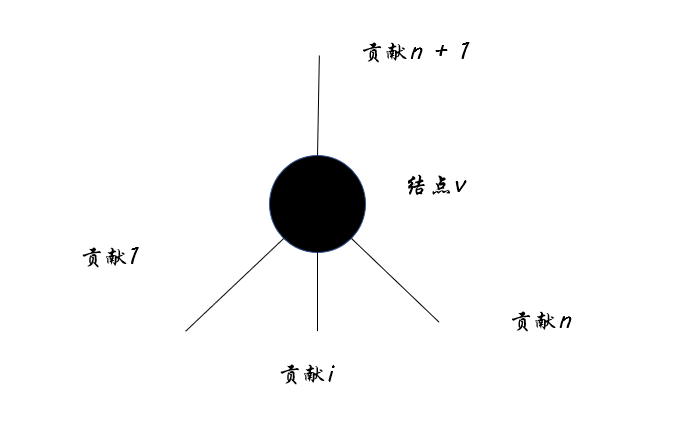
对于所有可能的路径的贡献值的累加,且贡献值需大于等于0。
- 白的比黑的多,有分, 这时我们选上这棵子树
- 黑的比白的多,没分, 这时我们放弃这棵子树
不妨设f[u]代表u结点的最大值。故
\large f[u]=c[u]+\sum_{v \in son_u}max(0,f[v])假如用暴力写法,就是对于每个结点u,暴力搜索所有的相邻结点,利用dfs暴力搜索。也就是以每个结点为棵出发,枚举n次dfs,但是结点最大为2∗10^5 这个暴力算法显然会超时,考虑如何优化。
算法优化
对于从下往上的贡献,可以利用从下往上的dfs树形dp进行获取,难求的是刨去以v为根的子树的贡献值,也就是向上走的那部分。
设u为节点v的父节点,f[v]代表从下往上以v为根的 白点数减去黑点数 的 最大值,g[v]代表最终的最大值。
根据刨去以v为根的子树的贡献值这个思想,可以发现:
\large add=g[u]−max(0,f[v])注:
fa[v]=u
就是刨去以v为根的子树的贡献值。写出状态转移方程:
\large g[v] =
\left\{\begin{matrix}
f[v] & if \ v = root \\
f[v]+max(0,g[u]-max(0,f[v]))& if \ v \neq root
\end{matrix}\right.
因此思路:
- ① 从下往上树形
dp,计算f[v] - ② 从上往下换根
dp,计算g[v]
Code
#include <bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10, M = N << 1;
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int f[N];
int g[N];
int c[N]; // 颜色
int n; // 节点数量
// 以1号节点为根,跑一遍dfs,填充每个节点的cnt1-cnt2的最大值
void dfs1(int u, int fa) {
f[u] = c[u]; // 1:白色,-1黑色,正好与 cnt1-cnt2一致,初始值加上了老头子自己的养老钱
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u);
f[u] += max(0, f[v]); // 如果我儿子给我,那我就拿着;如果我儿子不给我钱,或者管我要钱,我就不理它!
}
}
// 换根dp
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
int val = g[u] - max(f[v], 0);
g[v] = f[v] + max(val, 0);
dfs2(v, u);
}
}
int main() {
// 初始化链式前向星
memset(h, -1, sizeof h);
cin >> n;
for (int i = 1; i <= n; i++) {
int x;
cin >> x;
c[i] = (x ? x : -1); // 白色c[i]=1,黑色c[i]=-1
}
for (int i = 1; i < n; i++) {
int a, b;
cin >> a >> b;
add(a, b), add(b, a);
}
// 第一次dfs
dfs1(1, 0);
// 它们两个是一个意思
g[1] = f[1];
// 换根dp
dfs2(1, 0);
// 输出答案
for (int i = 1; i <= n; i++) printf("%d ", g[i]);
return 0;
}
P3047 Nearby Cows G
题目大意
给你一棵 n 个点的树,点带权,对于每个节点求出距离它不超过 k 的所有节点权值和。
对于树中的某个节点而言,距离它不超过k的节点主要来源于两方面:
- 一个是该节点的子节点中距离该节点不超过距离
k的节点的权值和 - 一个是该节点向上沿着父节点方向不超过距离
k的点的权值和
对于子节点方向的节点的权值和,可以通过普通的树形DP计算出来。
1、状态表示
f[i][j]表示以i为根节点的子树中,距离i不超过j的子节点的权值和。
2、状态转移
\large f[u][j]=val[u]+\sum_{v \in son[u]}f[v][j−1] \ j \in [1,k]到节点u不超过距离k,即距离v=son[u]不超过k−1,然后加在一起即可。同时u节点本身也有贡献,因为u节点本身是不超过距离0的节点。
理解:父亲的生活费=
\sum(每个儿子给的生活费)+自己的社保金
void dfs1(int u, int fa) {
// 初始化:当遍历到u节点时,u的拆分状态中,最起码包含了自己的点权值
for (int i = 0; i <= k; i++) f[u][i] = val[u];
// 枚举u的每一个子节点
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue; // 如果是u的父亲,那么就跳过,保证只访问u的孩子
// 先递归,// 递归填充v节点的信息
dfs1(v, u);
// 再利用子节点信息更新父节点信息
for (int j = 1; j <= k; j++) f[u][j] += f[v][j - 1];
}
}
3、换根DP
这个题目本身是个无根树,如果我们认为规定编号为1的节点是根的话,那么对于祖宗节点1来说,f[1][k]就是距离1节点不超过距离k的节点的权值和。因为祖宗节点是没有父亲节点的,所以我们就不需要考虑沿着父节点方向的节点权值和。
令:g[u][j]表示所有到u节点的不超过距离j的节点的权值和。根据刚刚的分析:
\large g[1][j]=f[1][j]\ j \in [1,k]这个就是我们换根DP的 初始化。
注:我们完全可以去把每个点都当作根,然后暴力跑出答案,但是这个暴力做法的时间复杂度是
O(n^2)的,会超时。
所以当我们将祖宗节点从节点1换为另一个节点的时候,我们只能通过数学上的关系来计算出g数组元素的值。这个也是换根DP的意义。
我们看下面的图:
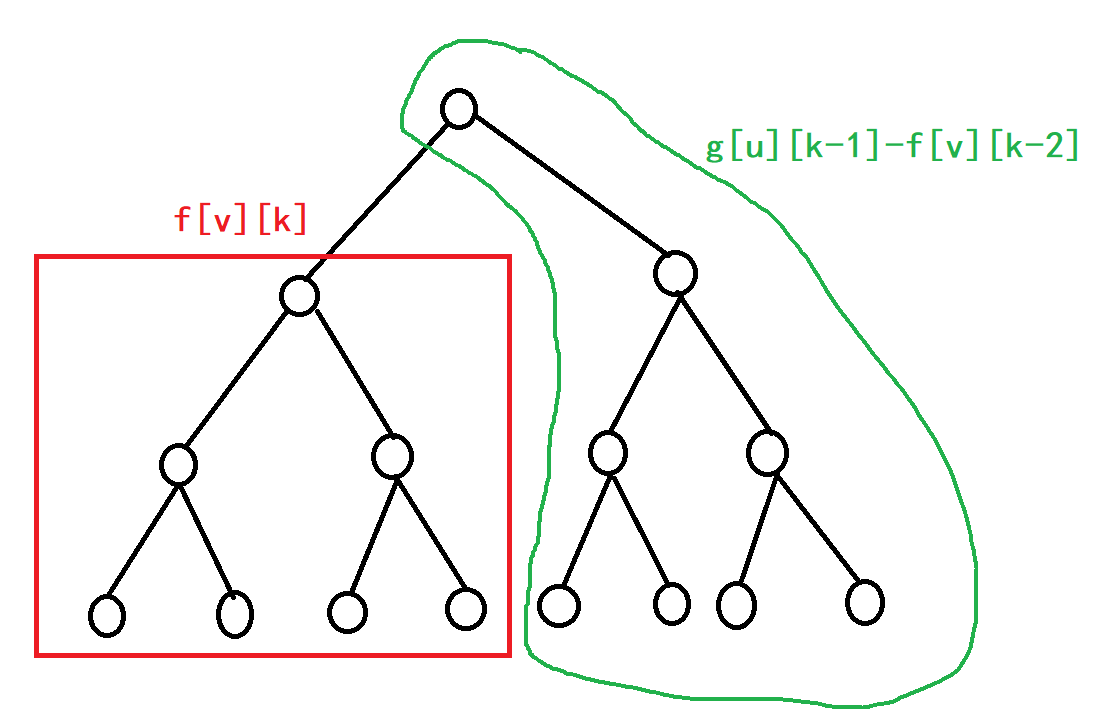
红色框是非常好理解的,以v为根的子树,在最远距离为k的限制下,写成f[v][k]。上面的部分,我们可以写成g[u][k-1]。因为到v不超过k的距离,即距离它的父亲节点不超过k−1的距离。
但是这么写对吗?
答案是不对的,g[u][k-1]和f[v][k]是有重复部分的。我们需要减去这段重复的部分,那么关键问题是重复部分如何表示?
重复部分肯定是出现在了红色框中,红色框中到u不超过距离k−1,即距离u不超过k-2,同时重复部分又恰好是节点v的子节点,所以这部分可以表示为:f[v][k-2]。
所以最终的结果就是:
\large g[v][k]=f[v][k]+g[u][k−1]−f[v][k−2]解释: ① 换根
DP时,由父推子,也就是用g[u][?] \rightarrow g[v][??]② 由于v需要向上,通过u去寻找点权和,而v \rightarrow u已经用去了1步,一共k步,现在就剩下了k-1步。 ③Q:那为什么不是f[u][k-1],而是g[u][k-1]呢? 因为u不光有向下的,还有向上的啊!我们现在不光要向下的,还要向上的,当然是g[u][k-1]啦! ④ 但是简单的这么整是不行的:g[u][k-1]与f[v][k]是存在交集的,如果简单加上就会造成一部分被算了两次!那么,是哪部分被算了两次呢? 答:对于u节点而言,g[u][k-1]与f[v][k]的交集,需要先走1步进入红框,这样,就用去了1步,也就是f[v][k-2]就是重复的部分,利用容斥原理去掉就行了,也就是g[v][k]=f[v][k]+g[u][k−1]−f[v][k−2]
细心的同学发现,这面的状态转移方程是有边界问题的:k-2是不是一定大于等于0呢?
如果k-2<=0咋办?会不会造成代码RE或者WA?
也就是说,上述方程成立的条件是k\geq 2的。
所以我们还得想一想\leq 1的时候。
如果k=0,g[v][0]其实就是val[v],因为不超过距离0的点只有本身。
如果k=1,那么g[v][1]其实就是f[v][1]+val[u],因为沿着父节点方向距离v不超过1的点,只有父节点,而树中,父节点是唯一的。沿着子节点方向,其实就是v的各个子节点,而这些子节点可以统统用f[v][1]表示。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10, M = N << 1;
const int K = 25;
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int f[N][K]; // f[i][j]:如果根是1号节点时,i号节点,最远走j步,可以获取到的所有点权和
int g[N][K];
int val[N]; // 点权数组
int n, k;
void dfs1(int u, int fa) {
// 初始化:当遍历到u节点时,u的拆分状态中,最起码包含了自己的点权值
for (int i = 0; i <= k; i++) f[u][i] = val[u];
// 枚举u的每一个子节点
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue; // 如果是u的父亲,那么就跳过,保证只访问u的孩子
// 先递归,// 递归填充v节点的信息
dfs1(v, u);
// 再利用子节点信息更新父节点信息
for (int j = 1; j <= k; j++) f[u][j] += f[v][j - 1];
}
}
// 换根dp
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
g[v][0] = val[v]; // 走0步,只有自己一个点
g[v][1] = f[v][1] + val[u]; // 走1步,包含自己下面子树一层+父节点
// 如果走2步及以上,最多k步以内
for (int j = 2; j <= k; j++) g[v][j] = f[v][j] + g[u][j - 1] - f[v][j - 2];
// 再递归,利用父更新子
dfs2(v, u);
}
}
int main() {
// 初始化链式前向星
memset(h, -1, sizeof h);
cin >> n >> k;
for (int i = 1; i < n; i++) { // n-1条边
int a, b;
cin >> a >> b;
add(a, b), add(b, a);
}
for (int i = 1; i <= n; i++) cin >> val[i]; // 点权
// 1、自底向上
dfs1(1, 0);
// 2、换根dp
for (int i = 0; i <= k; i++) g[1][i] = f[1][i];
dfs2(1, 0);
// 输出结果
for (int i = 1; i <= n; i++) cout << g[i][k] << endl;
return 0;
}
POJ3585 Accumulation Degree
题意
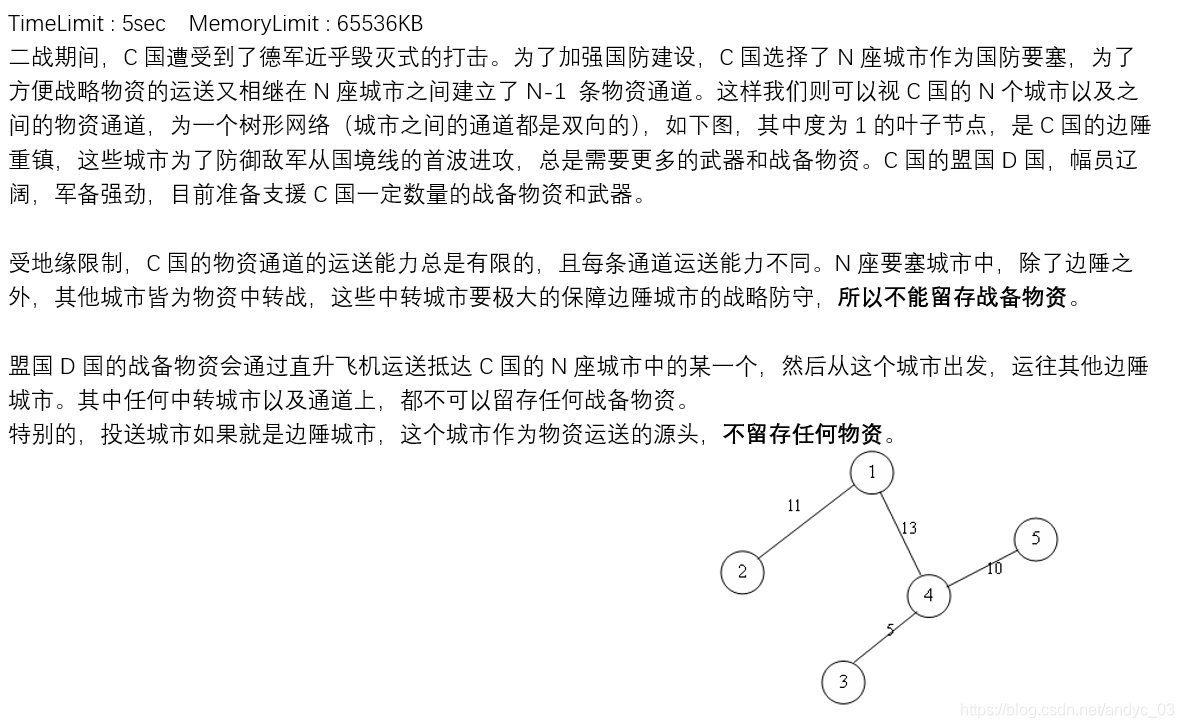

思路分析
这是一道 不定根 的树形DP问题,这类题目的特点是,给定一个树形结构,需要以每个结点为根进行一系列统计。我们一般通过两次扫描来求解此类问题:
- 1.第一次扫描,任选一个点为根,在 有根树 上执行一次树形
DP。 - 2.第二次扫描,从刚才选出的根出发,对整棵树执行一次
DFS,在每次递归前进行 自上而下 的推导,计算出 换根 之后的解。
样例分析
5个点, 4条边。当以4为起点时, 得到最大流量为26。
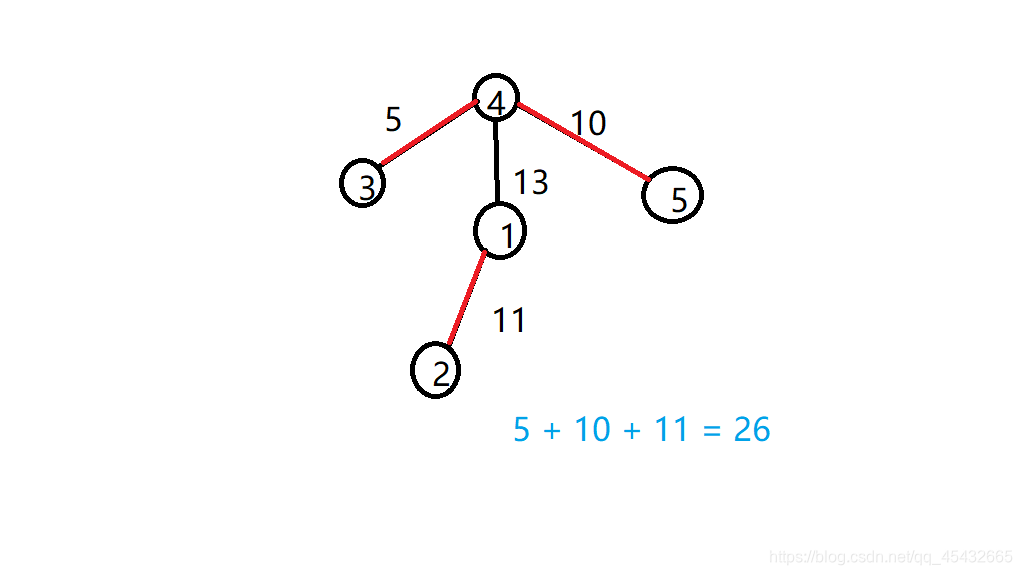
本题思路
-
① 选择
1号节点当做根节点,做一次树形DP,至下往上进行状态转移,更新f数组的值,f数组存的是f[i]是i的子树的最大流量(向下的)。 -
② 因为
1号节点没有向上的路径了,所以g[1]=f[1] -
③ 从
1号根节点出发, 扫描所有节点, 自顶往下进行更新g数组,g[x]代表以x为根节点的整棵树的最大总流量(不光是向下,还要有向上的)。
用du数组存节点的度,以便判断叶子结点:第一次搜索时,状态转移是如下代码所示:
- ① 如果
v是叶子结点,v的子树的最大流就是f[u] + w[u][v]这里的w[u][v]表示u到v的流量,代码中用w[i]表示 - ② 如果
v不是叶子结点, 流量就等于v的子树的最大流量和u到v的流量取最小值。
if(du[v] == 1) f[u] += w[i];
else f[u] += min(f[v], w[i]);
在进行g数组更新时也是类似的做法,由于是自上往下更新, 所以和上面会在更新存值时有一点不同,这里也是u \rightarrow v。
- ① 如果
u是叶子结点,g[v] = f[v] + w[i] - ② 如果
u不是叶子结点,g[u]的总流量减去u流向v的最大流,这就是u流向另外节点的总流量,再在这个总流量,和w[i]取一个最小值,就是v流向u的最大流,再加上v流向其他节点的总流量,就是以v为根节点的这棵树的最大总流量。
if (du[u] == 1)
g[v] = f[v] + w[i];
else
g[v] = f[v] + min(g[u] - min(f[v], w[i]), w[i]);
Code
#include <iostream>
#include <cstdio>
#include <vector>
#include <cstring>
using namespace std;
const int N = 2e5 + 10, M = N << 1;
int n, du[N];
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int f[N], g[N];
// 以1号点为根, 由子推父,先递归,再统计
void dfs1(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u);
if (du[v] == 1) // 如果v的度为1,也就是叶子
f[u] += w[i];
else
f[u] += min(f[v], w[i]);
}
}
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
if (du[u] == 1)
g[v] = f[v] + w[i];
else
g[v] = f[v] + min(g[u] - min(f[v], w[i]), w[i]);
// 先计算再递归
dfs2(v, u);
}
}
int main() {
// 加快读入
ios::sync_with_stdio(false), cin.tie(0);
int T;
cin >> T;
while (T--) {
// 初始化链式前向星
memset(h, -1, sizeof h);
idx = 0;
memset(du, 0, sizeof du);
memset(f, 0, sizeof f);
memset(g, 0, sizeof g);
cin >> n;
int a, b, c;
for (int i = 1; i < n; i++) { // 树,n-1条无向边
cin >> a >> b >> c;
add(a, b, c), add(b, a, c);
du[a]++, du[b]++; // 记录入度,无向图就不谈入度和出度了
}
// 第一遍dfs
dfs1(1, 0);
g[1] = f[1];
// 第二遍dfs
dfs2(1, 0);
int ans = 0;
for (int i = 1; i <= n; i++) ans = max(ans, g[i]);
cout << ans << endl;
}
return 0;
}
AcWing 1073. 树的中心
#include <bits/stdc++.h>
using namespace std;
const int N = 10010, M = N << 1;
const int INF = 0x3f3f3f3f;
int n; // n个节点
int mx1[N]; // mx1[u]:u节点向下走的最长路径的长度
int mx2[N]; // mx2[u]:u节点向下走的次长路径的长度
int id[N]; // id[u]:u节点向下走的最长路径是从哪一个节点下去的
int up[N]; // up[u]:u节点向上走的最长路径的长度
// 邻接表
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
// 功能:以u为根,向叶子进行递归,利用子节点返回的最长信息,更新自己的最长和次长,并记录最长是从哪个节点来的
void dfs1(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
// 递归完才能有数据
dfs1(v, u);
int x = mx1[v] + w[i]; // u问到:儿子v可以带我走多远?
if (mx1[u] < x) { // 更新最长
mx2[u] = mx1[u]; // ① 更新次长
mx1[u] = x; // ② 更新最长
id[u] = v; // ③ 记录最长来源
} else if (mx2[u] < x) // 更新次长
mx2[u] = x;
}
}
// 功能:完成向上的信息填充
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
// 二者取其一
if (id[u] == v)
up[v] = max(mx2[u], up[u]) + w[i];
else
up[v] = max(mx1[u], up[u]) + w[i];
// 递归
dfs2(v, u);
}
}
int main() {
memset(h, -1, sizeof h);
cin >> n;
for (int i = 1; i < n; i++) {
int a, b, c;
cin >> a >> b >> c;
add(a, b, c), add(b, a, c);
}
dfs1(1, 0); // 选择任意一个节点进行dfs,用儿子更新父亲的统计信息
dfs2(1, 0); // 向上
int res = INF;
for (int i = 1; i <= n; i++) res = min(res, max(mx1[i], up[i]));
printf("%d\n", res);
return 0;
}
P6419 Kamp
题目大意
一棵树上有一些点有人,边有通过的长度,然后对于每个点,你从这个点出发经过所有人(不用回到原来位置)的最短时间。 其它人不会动,只有你去找人。
思路
需要存储较多信息但并不算太难想的换根dp
先将问题转化:变成求从第i个点出发,将所有人都送回家后在回到i这个节点的最短路径,记作g[i]
最后我们要求解的答案 f[i]=g[i]-mx[i]
mx[i]为从i这个节点出发的最长路径长度,这条路我们可以考虑最后出发,这样送回去后并不需要返回原点了。
这里我们再多记录一些东西,这些是属于子树内的信息,一遍树形dfs即可求解:
f[i]表示将i这个节点子树的所有人都送回家并回到i的最短路径mx1[i]表示i节点子树的最长链的长度mx2[i]表示i节点子树的次长链的长度id[i]表示i节点的最长链属于哪个子树sz[i]表示 节点子树中被标记的节点的数量 这些具体看代码,感觉是典中典
/*
第一次dfs,先递归子节点v,利用子节点v提供的信息,更新父节点u的统计信息
统计信息包括:
① mx1[u]:以u为根的子树中,u可以走的最长距离.每次变更是通过mx1[u]=max(mx1[v]+w[i])更新的
② mx2[u]:以u为根的子树中,u可以走的次长距离
③ id[u]: 以u为根的子树中,当获取到u可以走的最长距离时,它第一个经过的点记录到id[u]中
④ sz[u]: 以u为根的子树中,有多少个需要接的人员
⑤ f[u]: 以u为根的子树中,从u出发,接完子树中所有人员,并且,返回到u,所需要的时间
*/
void dfs1(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u); // 上来先递归u的子节点v,因为v中在初始化读入时,已经初始化了sz[v]=1,所以,可以利用这个进行更新sz[u]+=sum(sz[v])
if (sz[v] == 0) continue; // 如果v里面没有需要接的人,那么以v为根的子树不会对u为根的子树产生贡献,放过v子树
// 如果进入到这里,说明v子树里面有需要接的人,会对u为根的子树产生贡献,需要讨论
f[u] += f[v] + 2 * w[i];
// v子树里有人,那么v子树就一定要进去看看!所以一来一回的w[i]省不下
// v里面到底需要花费多少时间,记录在f[v]里了,所以,v子树的整体贡献=f[v]+2*w[i]
// 维护最长、次长、最长是经过哪个节点来的三件事
int x = mx1[v] + w[i]; // v在以v为根的子树中,能走到的最长路径记录在mx1[v]里,现在以子推父,父亲的以u为根的子树中,u能走到的最长路径记录到mx1[u]中
// 如果u的最长路径可能是通过v获取到的,那么 mx1[u]=mx1[v]+w[i]
if (x >= mx1[u]) {
mx2[u] = mx1[u]; // 最长变为次长
mx1[u] = x; // mx1[v]+w[i]变为最长
id[u] = v; // 记录u的最长路径中第一个节点走的是v
} else if (x > mx2[u]) // 如果小于最长,大于次长(注意:这里不需要等号,等号没用,当然,加上也不错)
mx2[u] = x; // 更新次长
// 汇总父节点u的接人个数
sz[u] += sz[v];
}
}
紧接着我们考虑第二遍自顶向下的dfs
我们可以做到更新
g[i] 从第i个点出发,将所有人都送回家后在回到i这个节点的最短路径
up[i] $i点非子树的最长链的长度
这里分类讨论:
if (sz[v] == k) {
g[v] = f[v],
up[v] = 0;
}
所有的节点都在v的子树内,那么, 这里比较容易理解,因为所有节点都在子树内,那么这两个答案自然就等价了,而非子树最长链也很显然为0
else if (sz[v] == 0) {
g[v] = g[u] + 2 * w[i]; // 如果从v出发,并且,向u方向前进,那么u的结果就是你的结果,但是,要加上两次跑路的代价
up[v] = max(up[u], mx1[u]) + w[i]; // 需要取u的上、下行最长路径PK+w[i]
}
这里既然v子树没有被标记的点,那么一切都由父节点继承过来了
else if (sz[v] && sz[v] != k) {
g[v] = g[u]; // 这个最难理解,见题解
if (id[u] == v) // 如果u的最长路径上第一个节点是v
up[v] = max(mx2[u], up[u]) + w[i];
else
up[v] = max(mx1[u], up[u]) + w[i];
}
v子树有标记的点,v子树外也有标记的点
这种情况下 g[v]=g[u],这里感觉是这道题最难理解的一个地方了,当我们计算f[u]的时候,因为v子树有标记的点,所有我们肯定有f[v]+2\times w_{u \rightarrow v} 这个价值加进来,那么我们现在倒过来再计算g[v],自然而然也会加上这个值(这里有点口胡,建议画图理解一下)
而这里终于能用到了次长链,如果u的最长链经过v,则用max(up[u],mx2[u])更新
up[v],否则就使用max(up[u],mx1[u])更新up[v]。
时间复杂度 O(n)
#include <bits/stdc++.h>
using namespace std;
const int N = 500010, M = N << 1;
#define int long long
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int n; // n个节点
int k; // k个需要接的人
// 以下的五个数组,是在递归中维护的数据,只有准备了这些数据,才能保证各种情况下我们都能提供正确的解答
int mx1[N]; // u的子树中最长链的长度
int mx2[N]; // u的子树中次长链
int sz[N]; // 以u为根的子树中是否有人
int id[N]; // id[u]:u的最长链条出发,第1个经过的节点是哪个节点
int up[N]; // 向上的最长路径:不在u的子树内,而是向u的父节点方向走,距离u最远的那个人的家到u的距离
// 根据黄海的习惯,换根DP的第一次结果我喜欢记录到f[]中,第二次的统计结果喜欢记录到g[]中
// 这一点可能与网上一些题解不太一致,请读者注意
int f[N]; // 以任意点为根(一般情况下,我喜欢以节点1为根),记录:从u出发把u子树上的人都送回家再回到u所需要的时间
int g[N]; // 不管以哪点为根出发,记录:从u出发把所有点都送回家再回到u的最短时间
/*
本题其实是两个子问题的综合题:
1、你可以挑选任意一个点作为根出发,然后dfs走完全部的有人的节点,然后返回到根,这时当根节点确定时,这个总时间是确定的。
时间的相关条件包括:走了哪些路径(一来一回走两遍),路径的边权值,是从哪个根出发的(这个很好理解,从一个离大家都近的地方出发,肯定比
从欧洲出发要快吧~)。
2、如果只是最终都要回到根,那上面的逻辑跑多次以不同节点为根的dfs就行,也就是暴力换根;当然,我们嫌人家O(N^2)太慢,也可以优化一下:
采用换根dp,两次dfs,优化为O(N)的。
但这样肯定是不行的,原因是题目中隐藏了一个条件:最后一次送完人,不用回到根起点!!!
这个非常重要!!就是因为它才导致后面的讨论、存储统计信息非常麻烦!!!
*/
/*
第一次dfs,先递归子节点v,利用子节点v提供的信息,更新父节点u的统计信息
统计信息包括:
① mx1[u]:以u为根的子树中,u可以走的最长距离.每次变更是通过mx1[u]=max(mx1[v]+w[i])更新的
② mx2[u]:以u为根的子树中,u可以走的次长距离
③ id[u]: 以u为根的子树中,当获取到u可以走的最长距离时,它第一个经过的点记录到id[u]中
④ sz[u]: 以u为根的子树中,有多少个需要接的人员
⑤ f[u]: 以u为根的子树中,从u出发,接完子树中所有人员,并且,返回到u,所需要的时间
*/
void dfs1(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u); // 上来先递归u的子节点v,因为v中在初始化读入时,已经初始化了sz[v]=1,所以,可以利用这个进行更新sz[u]+=sum(sz[v])
if (sz[v] == 0) continue; // 如果v里面没有需要接的人,那么以v为根的子树不会对u为根的子树产生贡献,放过v子树
// 如果进入到这里,说明v子树里面有需要接的人,会对u为根的子树产生贡献,需要讨论
f[u] += f[v] + 2 * w[i];
// v子树里有人,那么v子树就一定要进去看看!所以一来一回的w[i]省不下
// v里面到底需要花费多少时间,记录在f[v]里了,所以,v子树的整体贡献=f[v]+2*w[i]
// 维护最长、次长、最长是经过哪个节点来的三件事
int x = mx1[v] + w[i]; // v在以v为根的子树中,能走到的最长路径记录在mx1[v]里,现在以子推父,父亲的以u为根的子树中,u能走到的最长路径记录到mx1[u]中
// 如果u的最长路径可能是通过v获取到的,那么 mx1[u]=mx1[v]+w[i]
if (x >= mx1[u]) {
mx2[u] = mx1[u]; // 最长变为次长
mx1[u] = x; // mx1[v]+w[i]变为最长
id[u] = v; // 记录u的最长路径中第一个节点走的是v
} else if (x > mx2[u]) // 如果小于最长,大于次长(注意:这里不需要等号,等号没用,当然,加上也不错)
mx2[u] = x; // 更新次长
// 汇总父节点u的接人个数
sz[u] += sz[v];
}
}
/* 换根DP
统计信息(以父更子,所以一般写作g[v])
① g[v] : 不再拘泥于只能向下统计,也包括向上的统计信息,全带上,我想知道以v为根出发需要多长时间把所有人都送回家,并且回到v点的时间是多少
② up[v]: v向上走的最远路径是多少
③
*/
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
/*
情况1:
所有的节点都在v的子树内,那么,这里比较容易理解,因为所有节点都在子树内,
那么这两个答案自然就等价了,而非子树最长链也很显然为0
*/
if (sz[v] == k) {
g[v] = f[v];
up[v] = 0;
}
/*
v子树没有被标记的点,那么一切都由父节点继承过了了
*/
else if (sz[v] == 0) {
g[v] = g[u] + 2 * w[i]; // 如果从v出发,并且,向u方向前进,那么u的结果就是你的结果,但是,要加上两次跑路的代价
up[v] = max(up[u], mx1[u]) + w[i]; // 需要取u的上、下行最长路径PK+w[i]
}
// v子树有标记的点,v子树外也有标记的点
else if (sz[v] && sz[v] != k) {
g[v] = g[u]; // 这个最难理解,见题解
if (id[u] == v) // 如果u的最长路径上第一个节点是v
up[v] = max(mx2[u], up[u]) + w[i];
else
up[v] = max(mx1[u], up[u]) + w[i];
}
// 套路
dfs2(v, u);
}
}
signed main() {
// 初始化链式前向星
memset(h, -1, sizeof h);
cin >> n >> k; // n个节点,要接k个人
for (int i = 1; i < n; i++) { // n-1条边
int a, b, c;
cin >> a >> b >> c;
add(a, b, c), add(b, a, c);
}
for (int i = 1; i <= k; i++) {
int x;
cin >> x;
sz[x] = 1; // x节点有一个人
}
// 第一次dfs
dfs1(1, 0);
g[1] = f[1];
// 第二次dfs
dfs2(1, 0);
// 遍历所有节点,以每个点为根出发,输出时间的最小值
for (int i = 1; i <= n; i++) cout << g[i] - max(up[i], mx1[i]) << endl;
}
V-Subtree
https://blog.csdn.net/Emm_Titan/article/details/123875298 https://blog.csdn.net/2303_76385579/article/details/131923964
题意
给定一棵 N 个节点的树,现在需要将每一个节点染成黑色或白色。
对于每一个节点 i,求强制把第 i 节点染成黑色的情况下,所有的黑色节点组成一个联通块的染色方案数,答案对 M 取模。
分析
题目要求我们求出对每一个点强制染黑的情形的答案,故考虑采用换根 DP。
先计算钦定 1 号点为根并染黑的方案数。
状态转移方程
① f[u]:将 u 号点染黑,且其子树内黑点构成连通块的方案数。易见,对于其每一个子节点 v,都有染黑和不染黑两种选择:染黑则方案数为 f_v ;不染黑则 v 的整棵子树都只能为白,方案数为 1。故\displaystyle \large f_u= \prod_{v \in son_u} (f_v+1)
② g[u]:注意!这里的g[u]与一般的换根DP不一样!
此处:g[u]表示u的父系带来的方案数。
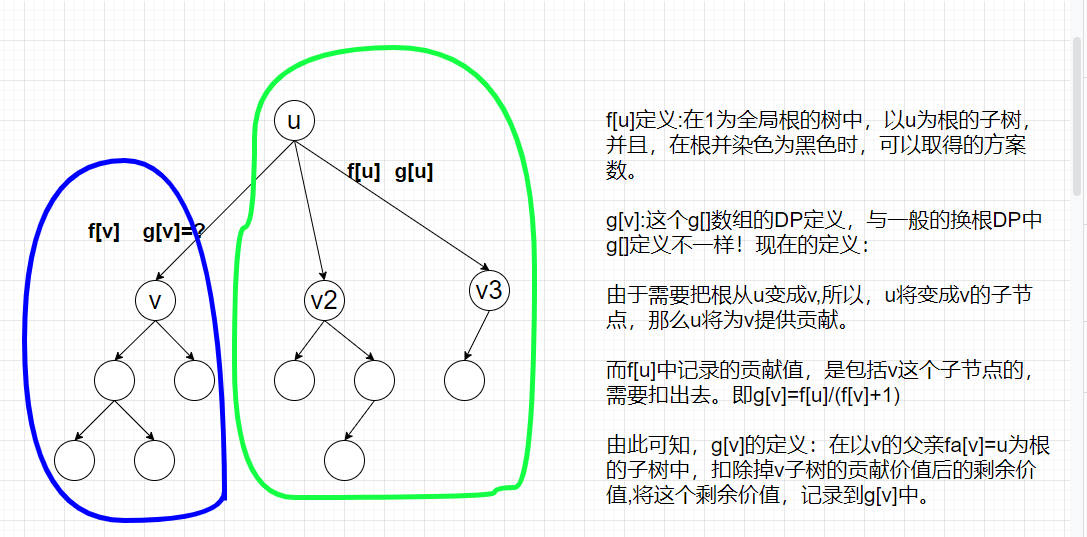
答案
对于以v为全局根的树而言,f[v]*g[v]就是答案。其实是左边蓝色线内的所有可能方案数,乘以,右边绿色线内的所有可能方案数,是就是所有方案数。
最后,所以节点逐个输出自己的f[i]*g[i]就可以了。
解释:
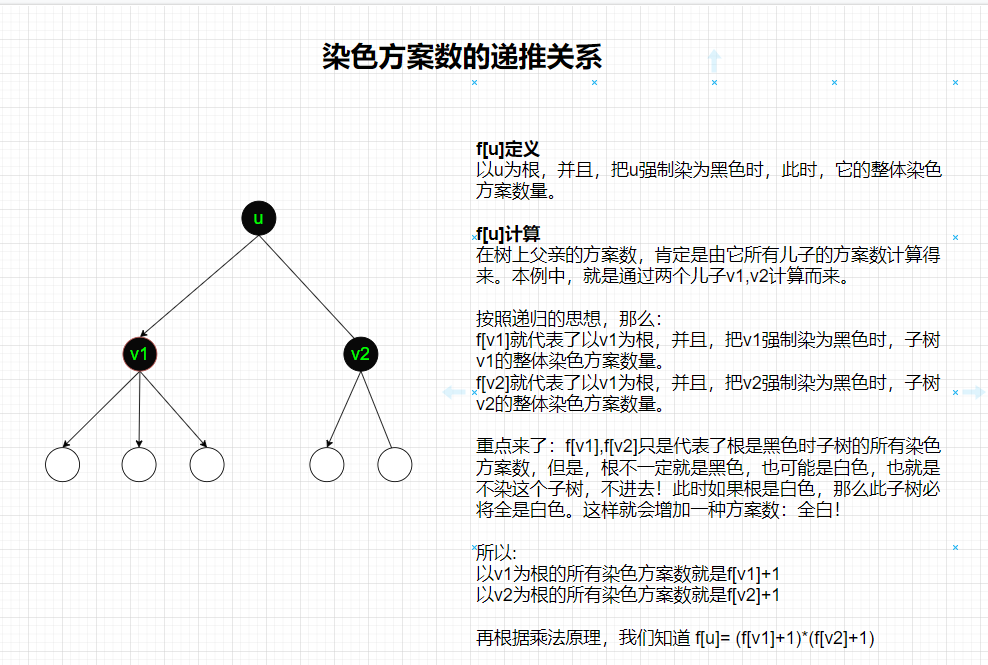
初始化
当 u 为叶子时,显然 f[u] =1,与初始化要求相同。
解释:对于每一个点,求强制给该点染上黑色时,整棵树上的黑点构成一个连通块的染色方案数。 这是题目的要求!当一个子树中只有一个点时,还要强制给该点染上黑色,那就只有一种方案。
第一遍dfs
void dfs1(int u, int fa) {
f[u] = 1; // 以u为根的子树,不管它是不是有子孙节点,最起码可以把u染成黑色,这样就可以有1种方案
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u);
f[u] = f[u] * (f[v] + 1) % mod; // 全白也是一种方案,对于v子树而言,它并不是只能提供以v染成黑色的所有方案,还有一种:v没有染成黑色的方案 }
第二遍dfs
现在考虑换根。
不难理解,如果v \in son[u],换根时消去 v 对 u 的贡献,求出 u 剩余贡献。
-
消去
v对u的贡献:\large x=\frac{f[u]}{f[v]+1} -
答案
\large g[v]=g[u] \times x
出现问题:模数不保证是质数,所以不能用直接乘逆元的方式来取模。
除法与模的处理办法
我们面对的是x=f[u]/(f[v]+1)
求方案数由于数值太大,肯定会爆掉long long,题目也很 温馨(恶心)给出了使用对mod取模的办法进行规避long long 越界。按国际惯例,应该是一路计算过来一路取模,计算式子中出现了除法,联想到了逆元。但费马小定理求逆元要求模必须是质数,现在给定的mod可没有说必须是质数,所以,无法使用逆元来求解。
不让用除法逆元那怎么处理除法+取模呢? 答案就是:前缀积+后缀积!!
因为根据题意,f[u]=(f[v_1]+1)*(f[v_2]+1)*(f[v_3]+1)*(f[v_4]+1)*....*
不让我用除法,我就不用除法,我只需要记录v的所有哥哥们的贡献乘积%mod 和 所有弟弟们的贡献乘积%mod:
\large pre[v]*suff[v]=f[u]/(f[v]+1)
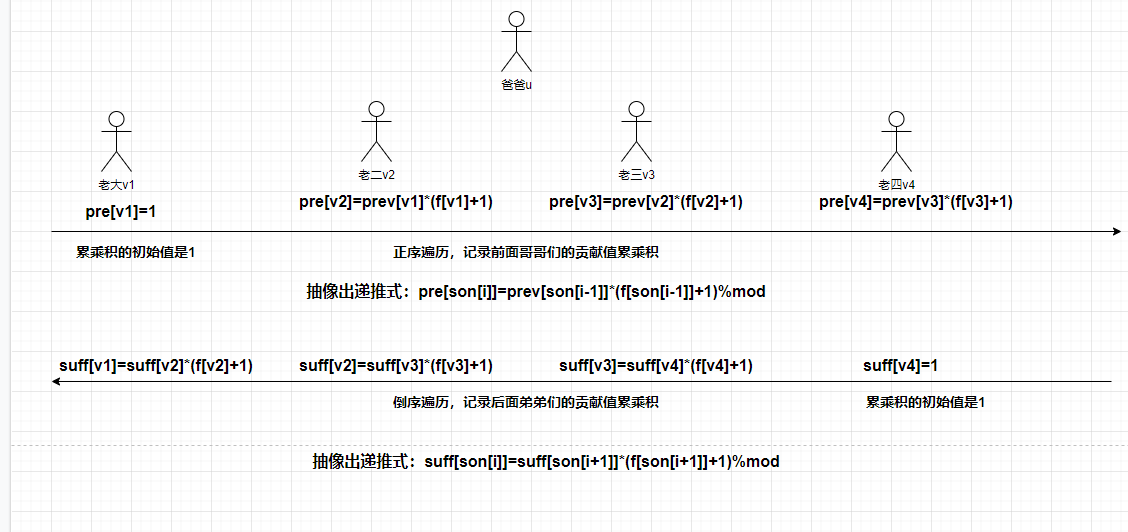
总结:
① f[u]除掉v贡献,也就等于v节点的哥哥们贡献前缀积、弟弟们贡献后缀积
②
计算前缀积、后缀积的三种办法
方法1
// 记录前缀积
int t1 = 1; // 前缀积取模后的值
for (int i = 0; i < son.size(); i++) { // 将儿子数组正着枚举
// 利用静态数组pre,记录每个节点的前缀积取模后的值
pre[son[i]] = t1; // 到我以前,所有结果的累乘积是多少
t1 = t1 * (f[son[i]] + 1) % mod; // 我完成后,需要把我的贡献也乘到累乘积中,以便我的下一个节点计算它的累乘积时使用
}
pre[]数组当桶使用,预留出N这么大的位置,因为执行完一次dfs1后,肯定会覆盖掉所有的节点,而每个节点,都可以理解为是某个人的儿子(老祖宗的儿子是1号节点),这样,所有的pre[]数组的内容值都将被填充,记录的是1 \sim N所有节点在自己的家族中,所有哥哥们的贡献值累乘和。即
pre[1]=1 累乘积初始值
\displaystyle pre[2]= pre[1] \times (f[1]+1) \% \ mod
\displaystyle pre[3]= pre[2] \times (f[2]+1) \% \ mod
\displaystyle pre[4]= pre[3] \times (f[3]+1) \% \ mod
...
\displaystyle pre[son[i]]= pre[son[i-1]] \times (f[son[i-1]]+1) \% \ mod
方法2
// 方法2:
if (son.size() > 0) pre[son[0]] = 1;
for (int i = 1; i < son.size(); i++)
pre[son[i]] = pre[son[i - 1]] * (f[son[i - 1]] + 1) % mod;
方法3
// 方法3:
for (int i = 0; i < son.size(); i++) {
if (i == 0) {
pre[son[i]] = 1;
continue;
}
pre[son[i]] = pre[son[i - 1]] * (f[son[i - 1]] + 1) % mod;
}
Code
#include <bits/stdc++.h>
using namespace std;
const int N = 100010, M = N << 1;
#define int long long
#define endl "\n"
// 链式前向星
int e[M], h[N], idx, w[M], ne[M];
void add(int a, int b, int c = 0) {
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
int f[N]; // 在以1为全局根的情况下,f[i]记录以i为根的子树,并且,把i染成黑色时,i为根的子树中所有可能的染色方案数量
int g[N];
int mod; // 对 mod 值取模
int pre[N]; // pre[i]:记录i节点的前缀积对mod取模后的值
int suff[N]; // suff[i]:记录i节点的后缀和对mod取模后的值
// 先递归再统计,以子填父,用儿子们的贡献更新父亲的值。最底层儿子,也就是叶子的贡献值是1,也就是只把它染成黑色,对于这个叶子的父亲而言,
// 它统计方案时,它认为这个儿子提供的方案数是2,因为儿子也可以不染色,也就是白色。当然,儿子也可以染成黑色,所以它理解为2。
void dfs1(int u, int fa) {
f[u] = 1; // 以u为根的子树,不管它是不是有子孙节点,最起码可以把u染成黑色,这样就可以有1种方案
vector<int> son; // 记录u有哪些儿子,方便后的计算。不使用链式前向星直接枚举的原因在于前向星只能正序枚举,
// 本题目中还需要倒序枚举,前向星记录的是单链表,不是双链表,无法倒序枚举,只能是跑一遍,记录下来,然后再倒着枚举
// 如此,在本题中,链式前向星就不如邻接表来的快,邻接表就是可以for(int i=0;i<edge[i].size();i++),也可以for(int i=edge[i].size()-1;i>=0;i--)
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
dfs1(v, u);
f[u] = f[u] * (f[v] + 1) % mod; // 全白也是一种方案,对于v子树而言,它并不是只能提供以v染成黑色的所有方案,还有一种:v没有染成黑色的方案数。
// 而此时,由于v没有染成黑色,所以,v子树就没有进去染色,也就是整个v子树全都是白色,这算是一种特殊的染色方案,也就是啥都不染。
// 所以 f[v]+1 就是v子树的所有贡献值,而f[u]需要把自己所有儿子的共献值累乘起来才是自己的贡献值。
son.push_back(v); // 将子节点加入集合,方便之后操作
}
// 记录前缀积
int t1 = 1; // 前缀积取模后的值
for (int i = 0; i < son.size(); i++) { // 将儿子数组正着枚举
// 利用静态数组pre,记录每个节点的前缀积取模后的值
pre[son[i]] = t1; // 到我以前,所有结果的累乘积是多少
t1 = t1 * (f[son[i]] + 1) % mod; // 我完成后,需要把我的贡献也乘到累乘积中,以便我的下一个节点计算它的累乘积时使用
}
// 记录后缀积
int t2 = 1; // 后缀积取模后的值
for (int i = son.size() - 1; i >= 0; i--) { // 将儿子数组倒着枚举
// 利用静态数组suff,记录每个节点的后缀积取模后的值
suff[son[i]] = t2; // 到我以前,所有结果的累乘积是多少
t2 = t2 * (f[son[i]] + 1) % mod; // 我完成后,需要把我的贡献也乘到累乘积中,以便我的下一个节点计算它的累乘积时使用
}
}
void dfs2(int u, int fa) {
for (int i = h[u]; ~i; i = ne[i]) {
int v = e[i];
if (v == fa) continue;
// g[u] * (pre[v] * suff[v])解析:
// u给v带来的影响,不光是u为根的子树这些叶子的贡献,还有重要的一部份,就是u的fa[u]及其父、叔叔、大爷、爷爷、二爷爷、老太爷、二老太爷来来的方案数
// 这些由爹系带来的方案数,汇聚到g[u]里
g[v] = (g[u] * (pre[v] * suff[v] % mod) % mod + 1) % mod;
dfs2(v, u);
}
}
signed main() {
// 初始化链式前向星
memset(h, -1, sizeof h);
int n;
cin >> n >> mod;
for (int i = 1; i < n; i++) {
int a, b;
cin >> a >> b;
add(a, b), add(b, a);
}
dfs1(1, 0);
g[1] = 1; // 考虑出发时,所有儿子的贡献都没有交上来,那么初化值是1,否则连乘积没法乘上来
dfs2(1, 0);
for (int i = 1; i <= n; i++) cout << f[i] * g[i] % mod << endl;
}
AcWing 1148 秘密的牛奶运输
CF708C Centroids
https://blog.csdn.net/TheSunspot/article/details/118216638
https://www.cnblogs.com/DongPD/p/17498336.html