using namespace std;
const int N = 1010;
int n, m;
int f[N];
int main() {
cin >> n >> m;
// 01背包模板
for (int i = 1; i <= n; i++) {
int v, w;
cin >> v >> w;
for (int j = m; j >= v; j--)
f[j] = max(f[j], f[j - v] + w);
}
printf("%d\n", f[m]);
return 0;
}
```
### 七、$01$背包之恰好装满【扩展】
有$n$个体积和价值分别为$v_i$,$w_i$的物品,现从这些物品中挑选出总体积 恰好 为 $m$ 的物品,求所有方案中价值总和的最大值。
**输入**:包含多组测试用例,每一例的开头为两位整数 $n、m$,$(1<=n<=10000,1<=m<=1000)$,接下来有 $n$ 行,每一行有两位整数 $v_i、w_i(1<=v_i<=10000,1<=w_i<=100)$。
**输出**:为一行,即所有方案中价值总和的最大值。若不存在刚好填满的情况,输出$-1$。
测试用例:
```c++
3 4
1 2
2 5
2 1
3 4
1 2
2 5
5 1
```
答案:
```c++
6
-1
```
恰好装满:
* 求最大值时,除了$f[0]$为$0$,其他都初始化为无穷小 `-0x3f3f3f3f`
* 求最小值时,除了$f[0]$为$0$,其他都初始化为无穷大 `0x3f3f3f3f`
不必恰好装满:
全初始化为$0$
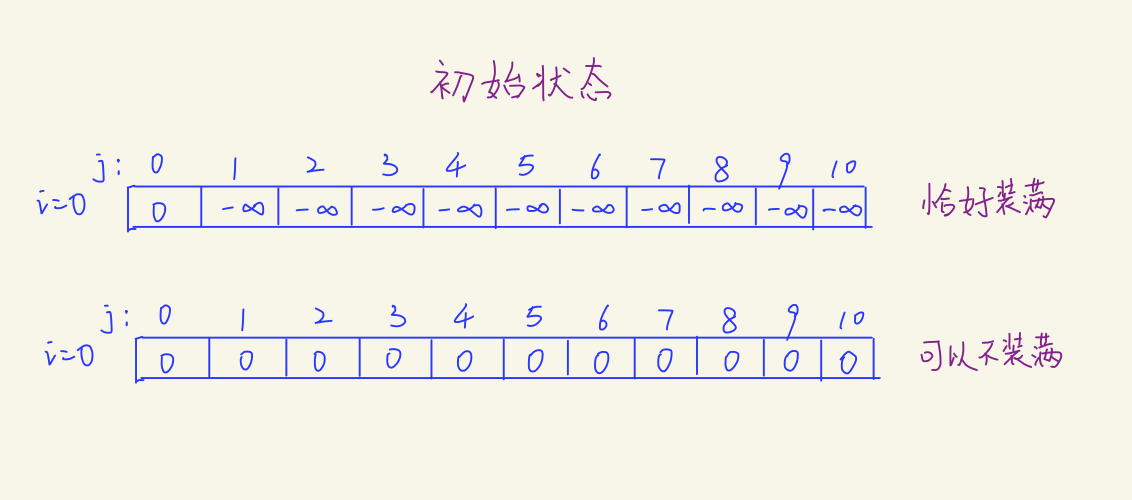
#### $Q:$为什么这样设置?
背包没恰好装满是无效状态, 恰好装满是有效状态。
当背包的状态为无效状态时,$f[i]$的值是$-INF$,这样就可以从状态转移矩阵中区分出有效状态和无效状态了。
回顾一下状态转移实现过程:
```cpp {.line-numbers}
for (int j = 1; j <= m; j++) {
f[i][j] = f[i - 1][j];
if (j >= v)
f[i][j] = max(f[i][j], f[i - 1][j - v] + w); //两种情况取最大值
}
```
$f[i][j]$ 的值是由 $f[i - 1][j],f[i - 1][j - w]$来推导出来的,也就是 $f[i][j]$ 的取值 只与前面的状态有关系,所有的状态都是从以前的状态来推导出来的。换句话说,所有的**有效状态**是从之前的**有效状态**和**无效状态**推导出来的!!!
目标:
通过初始化无效状态为$-INF$,在不改变原来代码的情况下,解决掉恰好装满的问题!
我们来分析一下有效状态与无效状态之间的转化关系:
先上结论:
| 前序状态$f[i - 1][j]$ | 前序状态$f[i - 1][j - w]$ | 当前状态$f[i][j]$ | 转移来源 |
| ----------------------------------------------------- | ----------------------------------------------------- | ----------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------- |
| 有效状态(满) | 有效状态(满) | 有效状态(满) | $max(f[i-1][j],f[i-1][j-w]+v)$ |
| 无效状态(不满) | 有效状态(满) | 有效状态(满) | $max(f[i-1][j-w]+v,-INF)$ |
| 有效状态(满) | 无效状态(不满) | 有效状态(满) | $max(f[i-1][j],-INF)$ |
| 无效状态(不满) | 无效状态(不满) | 无效状态(不满) | 转不过来了
$f[i][j] = max(f[i-1][j], f[i - 1][j - w] + v)$,$-INF$会被加上$v$,不再是$-INF$,但肯定是负数。 |
#### 无效状态的处理方法
上面表格中也提到了这个问题:$f[i][j] = max(f[i][j], f[i - 1][j - v] + w)$,如果两个前序状态都是无效状态,那么$-INF$会被加上$w$,不再是$-INF$,但肯定是负数。在最终结果判定中,我们可以认为是负数的,就是无效状态:**假设负无穷不是靠你简单加上几个小正数就能大于零的**~
#### 二维代码实现
```cpp {.line-numbers}
#include
using namespace std;
const int N = 10010;
int n, m, f[N][N];
int main() {
// 文件输入
freopen("2_QiaHaoFill.in", "r", stdin);
while (cin >> n >> m) {
memset(f, -0x3f, sizeof(f)); // 其它位置全部初始化为-INF
for (int i = 0; i < N; i++) f[i][0] = 0; // 第一列初始化为0
for (int i = 1; i <= n; i++) {
int w, v;
cin >> v >> w;
for (int j = v; j <= m; j++)
f[i][j] = max(f[i][j], f[i - 1][j - v] + w);
}
if (f[n][m] < 0)
puts("-1");
else
printf("%d\n", f[n][m]);
}
return 0;
}
```
#### 一维代码实现
```cpp {.line-numbers}
#include
using namespace std;
const int N = 10010;
int n, m, f[N];
int main() {
// 文件输入
freopen("2_QiaHaoFill.in", "r", stdin);
while (cin >> n >> m) {
memset(f, -0x3f, sizeof(f));
f[0] = 0;
for (int i = 1; i <= n; ++i) {
int v, w;
cin >> v >> w;
for (int j = m; j >= v; j--)
f[j] = max(f[j], f[j - v] + w);
}
if (f[m] < 0)
puts("-1");
else
printf("%d\n", f[m]);
}
return 0;
}
```