From 3bbd707d17f42550a085f63b35b6c9c6d25eb35a Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?=E9=BB=84=E6=B5=B7?= <10402852@qq.com>
Date: Fri, 15 Mar 2024 10:52:53 +0800
Subject: [PATCH] 'commit'
---
TangDou/AcWing/BeiBao/1013.md | 30 ++++++++++++++----------------
1 file changed, 14 insertions(+), 16 deletions(-)
diff --git a/TangDou/AcWing/BeiBao/1013.md b/TangDou/AcWing/BeiBao/1013.md
index b59f7cd..5846188 100644
--- a/TangDou/AcWing/BeiBao/1013.md
+++ b/TangDou/AcWing/BeiBao/1013.md
@@ -78,20 +78,18 @@ $3$个公司,$3$台机器,**机器都是一样的,一样的,记住,一
### 二、分组背包
-转换成 **分组背包问题** ,做 **等价变换**
+**套模型**:转换成 **分组背包问题** ,做 **等价变换**
① 第$i$个公司就是第$i$个分组
-② 每个分组中可以一台也不要,可以要一台,可以要两台,...,可以要$S_i$台
+② 每个分组中可以一台也不要$f[i][j]=f[i-1][j]$,如果背包能装的下的前提下:
+- 要一台(类比为第$1$个)
+- 要两台(类比为第$2$个)
+- ...
+- 要$S_i$台(类比为第$S_i$个)
-**分组背包** 的 **闫氏DP分析法**
-
-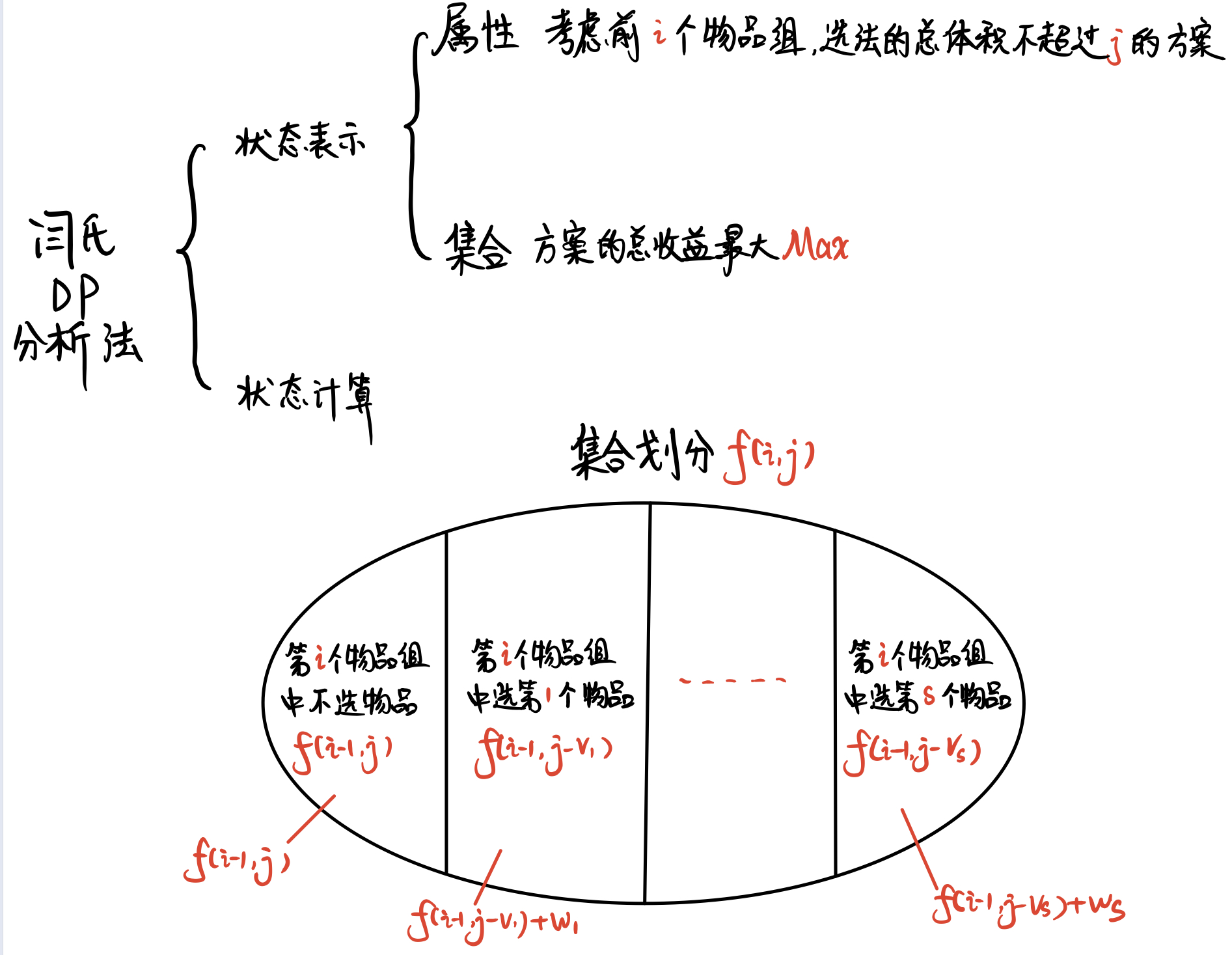 -
-初始状态 :$f[0][0]$
-
-目标状态 :$f[N][M]$
+本题特殊的地方就是需要求 **最优解时的路径** ,而且可能要的是 **字典序最小** 的路径。
### 三、不同$OJ$此题的差别
@@ -119,13 +117,13 @@ output
```
**解决办法**
-* **$dfs$暴搜法**
-$dfs$保证找到最大答案的时候就是字典序最少的,因为我从$1$号-$n$号枚举用的多少机器,用的机器数量也是由少到多。当最后得到答案相等的情况下就不用需要比较字典序了,直接$return$,只有碰到大小不一的时候才更新答案机器数。
+* ① **$dfs$暴搜法**
+$dfs$保证找到最大答案的时候就是字典序最少的,因为我从$1 \sim n$号枚举用的多少机器,用的机器数量也是由少到多。当最后得到答案相等的情况下就不用需要比较字典序了,直接$return$,只有碰到大小不一的时候才更新答案机器数。
-* **$dp$+记录路径法**
- * 如果使用$val > f[i][j]$转移,$f[i][j]$中记录的是第一次找到的最大值,由于输出路径是 **倒序** 输出的,所以打印出来的路径是字典序最大的。
+* ② **$dp$+记录路径法**
+ * 如果$val > f[i][j]$转移,打印出来的路径是字典序最大的
- * 如果使用$val >= f[i][j]$转移,$f[i][j]$中记录的是最后一次找到的最大值,由于输出路径是 **倒序** 输出的,所以打印出来的路径是字典序最小的。
+ * 如果$val \geq f[i][j]$转移,打印出来的路径是字典序最小的
>**$Q$:为什么加上等号就是按字典序最小输出呢?**
```cpp {.line-numbers}
@@ -137,9 +135,9 @@ for (int k = 1; k <= j; k++) {
}
}
```
-**答**: 奇妙的地方是`f[i-1][j-k]`。
-$k$的含义是当前分组中的物品个数,是由小到大的。而这里的计算式是$j-k$,这个东西在$k$前面的符号是负数,也就是$k$越小,值越大,$k$越大,值越小。按个循环逻辑,随着$k$的长大,就会枚举到更小的$j-k$,也就是枚举到更小的字典序。如果没有等号,就是$k$越来越大时,$j-k$越来越小,当价值一样时,越来越小的个数无法更新结果,反之,如果有等号,就是获取到字典序。
+**答**: 观察`f[i-1][j-k]`,计算式是$j-k$,$k$前面的符号是负号,也就是$k$越小,$j-k$越大;$k$越大,值越小。按这个逻辑,随着$k$长大,就会枚举到更小的$j-k$。
+如果没有等号,是$k$越来越大时,$j-k$越来越小,当价值一样时,越来越小的个数无法更新结果,反之,如果有等号,就是获取到字典序。
**二维数组写法**
-
-初始状态 :$f[0][0]$
-
-目标状态 :$f[N][M]$
+本题特殊的地方就是需要求 **最优解时的路径** ,而且可能要的是 **字典序最小** 的路径。
### 三、不同$OJ$此题的差别
@@ -119,13 +117,13 @@ output
```
**解决办法**
-* **$dfs$暴搜法**
-$dfs$保证找到最大答案的时候就是字典序最少的,因为我从$1$号-$n$号枚举用的多少机器,用的机器数量也是由少到多。当最后得到答案相等的情况下就不用需要比较字典序了,直接$return$,只有碰到大小不一的时候才更新答案机器数。
+* ① **$dfs$暴搜法**
+$dfs$保证找到最大答案的时候就是字典序最少的,因为我从$1 \sim n$号枚举用的多少机器,用的机器数量也是由少到多。当最后得到答案相等的情况下就不用需要比较字典序了,直接$return$,只有碰到大小不一的时候才更新答案机器数。
-* **$dp$+记录路径法**
- * 如果使用$val > f[i][j]$转移,$f[i][j]$中记录的是第一次找到的最大值,由于输出路径是 **倒序** 输出的,所以打印出来的路径是字典序最大的。
+* ② **$dp$+记录路径法**
+ * 如果$val > f[i][j]$转移,打印出来的路径是字典序最大的
- * 如果使用$val >= f[i][j]$转移,$f[i][j]$中记录的是最后一次找到的最大值,由于输出路径是 **倒序** 输出的,所以打印出来的路径是字典序最小的。
+ * 如果$val \geq f[i][j]$转移,打印出来的路径是字典序最小的
>**$Q$:为什么加上等号就是按字典序最小输出呢?**
```cpp {.line-numbers}
@@ -137,9 +135,9 @@ for (int k = 1; k <= j; k++) {
}
}
```
-**答**: 奇妙的地方是`f[i-1][j-k]`。
-$k$的含义是当前分组中的物品个数,是由小到大的。而这里的计算式是$j-k$,这个东西在$k$前面的符号是负数,也就是$k$越小,值越大,$k$越大,值越小。按个循环逻辑,随着$k$的长大,就会枚举到更小的$j-k$,也就是枚举到更小的字典序。如果没有等号,就是$k$越来越大时,$j-k$越来越小,当价值一样时,越来越小的个数无法更新结果,反之,如果有等号,就是获取到字典序。
+**答**: 观察`f[i-1][j-k]`,计算式是$j-k$,$k$前面的符号是负号,也就是$k$越小,$j-k$越大;$k$越大,值越小。按这个逻辑,随着$k$长大,就会枚举到更小的$j-k$。
+如果没有等号,是$k$越来越大时,$j-k$越来越小,当价值一样时,越来越小的个数无法更新结果,反之,如果有等号,就是获取到字典序。
**二维数组写法**