|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| .github | 3 weeks ago | |
| assets | 3 weeks ago | |
| examples | 3 weeks ago | |
| raganything | 3 weeks ago | |
| .gitignore | 3 weeks ago | |
| .pre-commit-config.yaml | 3 weeks ago | |
| LICENSE | 3 weeks ago | |
| MANIFEST.in | 3 weeks ago | |
| README.md | 3 weeks ago | |
| README_zh.md | 3 weeks ago | |
| env.example | 3 weeks ago | |
| requirements.txt | 3 weeks ago | |
| setup.py | 3 weeks ago | |
README.md
🚀 RAG-Anything: All-in-One RAG System


🎉 News
- [2025.07.04]🎯📢 RAGAnything now supports query with multimodal content, enabling enhanced retrieval-augmented generation with integrated text, images, tables, and equations processing.
- [2025.07.03]🎯📢 RAGAnything has reached 1K🌟 stars on GitHub! Thank you for your support and contributions.
🌟 System Overview
Next-Generation Multimodal Intelligence
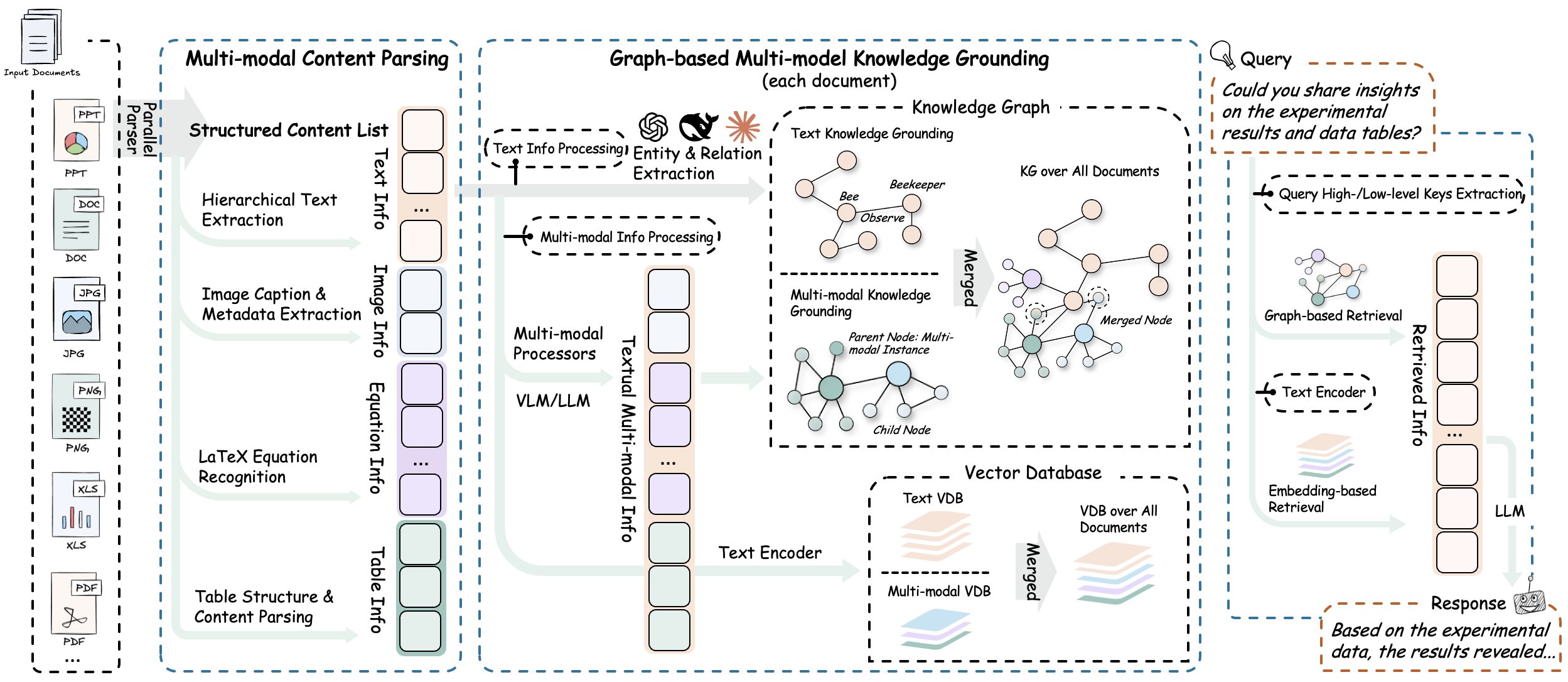
Modern documents increasingly contain diverse multimodal content—text, images, tables, equations, charts, and multimedia—that traditional text-focused RAG systems cannot effectively process. RAG-Anything addresses this challenge as a comprehensive All-in-One Multimodal Document Processing RAG system built on LightRAG.
As a unified solution, RAG-Anything eliminates the need for multiple specialized tools. It provides seamless processing and querying across all content modalities within a single integrated framework. Unlike conventional RAG approaches that struggle with non-textual elements, our all-in-one system delivers comprehensive multimodal retrieval capabilities.
Users can query documents containing interleaved text, visual diagrams, structured tables, and mathematical formulations through one cohesive interface. This consolidated approach makes RAG-Anything particularly valuable for academic research, technical documentation, financial reports, and enterprise knowledge management where rich, mixed-content documents demand a unified processing framework.
🎯 Key Features
- 🔄 End-to-End Multimodal Pipeline - Complete workflow from document ingestion and parsing to intelligent multimodal query answering
- 📄 Universal Document Support - Seamless processing of PDFs, Office documents, images, and diverse file formats
- 🧠 Specialized Content Analysis - Dedicated processors for images, tables, mathematical equations, and heterogeneous content types
- 🔗 Multimodal Knowledge Graph - Automatic entity extraction and cross-modal relationship discovery for enhanced understanding
- ⚡ Adaptive Processing Modes - Flexible MinerU-based parsing or direct multimodal content injection workflows
- 🎯 Hybrid Intelligent Retrieval - Advanced search capabilities spanning textual and multimodal content with contextual understanding
🏗️ Algorithm & Architecture
Core Algorithm
RAG-Anything implements an effective multi-stage multimodal pipeline that fundamentally extends traditional RAG architectures to seamlessly handle diverse content modalities through intelligent orchestration and cross-modal understanding.
1. Document Parsing Stage
The system provides high-fidelity document extraction through adaptive content decomposition. It intelligently segments heterogeneous elements while preserving contextual relationships. Universal format compatibility is achieved via specialized optimized parsers.
Key Components:
-
⚙️ MinerU Integration: Leverages MinerU for high-fidelity document structure extraction and semantic preservation across complex layouts.
-
🧩 Adaptive Content Decomposition: Automatically segments documents into coherent text blocks, visual elements, structured tables, mathematical equations, and specialized content types while preserving contextual relationships.
-
📁 Universal Format Support: Provides comprehensive handling of PDFs, Office documents (DOC/DOCX/PPT/PPTX/XLS/XLSX), images, and emerging formats through specialized parsers with format-specific optimization.
2. Multi-Modal Content Understanding & Processing
The system automatically categorizes and routes content through optimized channels. It uses concurrent pipelines for parallel text and multimodal processing. Document hierarchy and relationships are preserved during transformation.
Key Components:
-
🎯 Autonomous Content Categorization and Routing: Automatically identify, categorize, and route different content types through optimized execution channels.
-
⚡ Concurrent Multi-Pipeline Architecture: Implements concurrent execution of textual and multimodal content through dedicated processing pipelines. This approach maximizes throughput efficiency while preserving content integrity.
-
🏗️ Document Hierarchy Extraction: Extracts and preserves original document hierarchy and inter-element relationships during content transformation.
3. Multimodal Analysis Engine
The system deploys modality-aware processing units for heterogeneous data modalities:
Specialized Analyzers:
-
🔍 Visual Content Analyzer:
- Integrate vision model for image analysis.
- Generates context-aware descriptive captions based on visual semantics.
- Extracts spatial relationships and hierarchical structures between visual elements.
-
📊 Structured Data Interpreter:
- Performs systematic interpretation of tabular and structured data formats.
- Implements statistical pattern recognition algorithms for data trend analysis.
- Identifies semantic relationships and dependencies across multiple tabular datasets.
-
📐 Mathematical Expression Parser:
- Parses complex mathematical expressions and formulas with high accuracy.
- Provides native LaTeX format support for seamless integration with academic workflows.
- Establishes conceptual mappings between mathematical equations and domain-specific knowledge bases.
-
🔧 Extensible Modality Handler:
- Provides configurable processing framework for custom and emerging content types.
- Enables dynamic integration of new modality processors through plugin architecture.
- Supports runtime configuration of processing pipelines for specialized use cases.
4. Multimodal Knowledge Graph Index
The multi-modal knowledge graph construction module transforms document content into structured semantic representations. It extracts multimodal entities, establishes cross-modal relationships, and preserves hierarchical organization. The system applies weighted relevance scoring for optimized knowledge retrieval.
Core Functions:
-
🔍 Multi-Modal Entity Extraction: Transforms significant multimodal elements into structured knowledge graph entities. The process includes semantic annotations and metadata preservation.
-
🔗 Cross-Modal Relationship Mapping: Establishes semantic connections and dependencies between textual entities and multimodal components. This is achieved through automated relationship inference algorithms.
-
🏗️ Hierarchical Structure Preservation: Maintains original document organization through "belongs_to" relationship chains. These chains preserve logical content hierarchy and sectional dependencies.
-
⚖️ Weighted Relationship Scoring: Assigns quantitative relevance scores to relationship types. Scoring is based on semantic proximity and contextual significance within the document structure.
5. Modality-Aware Retrieval
The hybrid retrieval system combines vector similarity search with graph traversal algorithms for comprehensive content retrieval. It implements modality-aware ranking mechanisms and maintains relational coherence between retrieved elements to ensure contextually integrated information delivery.
Retrieval Mechanisms:
-
🔀 Vector-Graph Fusion: Integrates vector similarity search with graph traversal algorithms. This approach leverages both semantic embeddings and structural relationships for comprehensive content retrieval.
-
📊 Modality-Aware Ranking: Implements adaptive scoring mechanisms that weight retrieval results based on content type relevance. The system adjusts rankings according to query-specific modality preferences.
-
🔗 Relational Coherence Maintenance: Maintains semantic and structural relationships between retrieved elements. This ensures coherent information delivery and contextual integrity.
🚀 Quick Start
Initialize Your AI Journey

Installation
Option 1: Install from PyPI (Recommended)
# Basic installation
pip install raganything
# With optional dependencies for extended format support:
pip install 'raganything[all]' # All optional features
pip install 'raganything[image]' # Image format conversion (BMP, TIFF, GIF, WebP)
pip install 'raganything[text]' # Text file processing (TXT, MD)
pip install 'raganything[image,text]' # Multiple features
Option 2: Install from Source
git clone https://github.com/HKUDS/RAG-Anything.git
cd RAG-Anything
pip install -e .
# With optional dependencies
pip install -e '.[all]'
Optional Dependencies
[image]- Enables processing of BMP, TIFF, GIF, WebP image formats (requires Pillow)[text]- Enables processing of TXT and MD files (requires ReportLab)[all]- Includes all Python optional dependencies
⚠️ Office Document Processing Requirements:
- Office documents (.doc, .docx, .ppt, .pptx, .xls, .xlsx) require LibreOffice installation
- Download from LibreOffice official website
- Windows: Download installer from official website
- macOS:
brew install --cask libreoffice- Ubuntu/Debian:
sudo apt-get install libreoffice- CentOS/RHEL:
sudo yum install libreoffice
Check MinerU installation:
# Verify installation
mineru --version
# Check if properly configured
python -c "from raganything import RAGAnything; rag = RAGAnything(); print('✅ MinerU installed properly' if rag.check_mineru_installation() else '❌ MinerU installation issue')"
Models are downloaded automatically on first use. For manual download, refer to MinerU Model Source Configuration.
Usage Examples
1. End-to-End Document Processing
import asyncio
from raganything import RAGAnything
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
async def main():
# Initialize RAGAnything
rag = RAGAnything(
working_dir="./rag_storage",
llm_model_func=lambda prompt, system_prompt=None, history_messages=[], **kwargs: openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key="your-api-key",
**kwargs,
),
vision_model_func=lambda prompt, system_prompt=None, history_messages=[], image_data=None, **kwargs: openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=[
{"role": "system", "content": system_prompt} if system_prompt else None,
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}
]} if image_data else {"role": "user", "content": prompt}
],
api_key="your-api-key",
**kwargs,
) if image_data else openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key="your-api-key",
**kwargs,
),
embedding_func=EmbeddingFunc(
embedding_dim=3072,
max_token_size=8192,
func=lambda texts: openai_embed(
texts,
model="text-embedding-3-large",
api_key=api_key,
base_url=base_url,
),
),
)
# Process a document
await rag.process_document_complete(
file_path="path/to/your/document.pdf",
output_dir="./output",
parse_method="auto"
)
# Query the processed content
# Pure text query - for basic knowledge base search
text_result = await rag.aquery(
"What are the main findings shown in the figures and tables?",
mode="hybrid"
)
print("Text query result:", text_result)
# Multimodal query with specific multimodal content
multimodal_result = await rag.aquery_with_multimodal(
"Explain this formula and its relevance to the document content",
multimodal_content=[{
"type": "equation",
"latex": "P(d|q) = \\frac{P(q|d) \\cdot P(d)}{P(q)}",
"equation_caption": "Document relevance probability"
}],
mode="hybrid"
)
print("Multimodal query result:", multimodal_result)
if __name__ == "__main__":
asyncio.run(main())
2. Direct Multimodal Content Processing
import asyncio
from lightrag import LightRAG
from raganything.modalprocessors import ImageModalProcessor, TableModalProcessor
async def process_multimodal_content():
# Initialize LightRAG
rag = LightRAG(
working_dir="./rag_storage",
# ... your LLM and embedding configurations
)
await rag.initialize_storages()
# Process an image
image_processor = ImageModalProcessor(
lightrag=rag,
modal_caption_func=your_vision_model_func
)
image_content = {
"img_path": "path/to/image.jpg",
"img_caption": ["Figure 1: Experimental results"],
"img_footnote": ["Data collected in 2024"]
}
description, entity_info = await image_processor.process_multimodal_content(
modal_content=image_content,
content_type="image",
file_path="research_paper.pdf",
entity_name="Experimental Results Figure"
)
# Process a table
table_processor = TableModalProcessor(
lightrag=rag,
modal_caption_func=your_llm_model_func
)
table_content = {
"table_body": """
| Method | Accuracy | F1-Score |
|--------|----------|----------|
| RAGAnything | 95.2% | 0.94 |
| Baseline | 87.3% | 0.85 |
""",
"table_caption": ["Performance Comparison"],
"table_footnote": ["Results on test dataset"]
}
description, entity_info = await table_processor.process_multimodal_content(
modal_content=table_content,
content_type="table",
file_path="research_paper.pdf",
entity_name="Performance Results Table"
)
if __name__ == "__main__":
asyncio.run(process_multimodal_content())
3. Batch Processing
# Process multiple documents
await rag.process_folder_complete(
folder_path="./documents",
output_dir="./output",
file_extensions=[".pdf", ".docx", ".pptx"],
recursive=True,
max_workers=4
)
4. Custom Modal Processors
from raganything.modalprocessors import GenericModalProcessor
class CustomModalProcessor(GenericModalProcessor):
async def process_multimodal_content(self, modal_content, content_type, file_path, entity_name):
# Your custom processing logic
enhanced_description = await self.analyze_custom_content(modal_content)
entity_info = self.create_custom_entity(enhanced_description, entity_name)
return await self._create_entity_and_chunk(enhanced_description, entity_info, file_path)
5. Query Options
RAG-Anything provides two types of query methods:
Pure Text Queries - Direct knowledge base search using LightRAG:
# Different query modes for text queries
text_result_hybrid = await rag.aquery("Your question", mode="hybrid")
text_result_local = await rag.aquery("Your question", mode="local")
text_result_global = await rag.aquery("Your question", mode="global")
text_result_naive = await rag.aquery("Your question", mode="naive")
# Synchronous version
sync_text_result = rag.query("Your question", mode="hybrid")
Multimodal Queries - Enhanced queries with multimodal content analysis:
# Query with table data
table_result = await rag.aquery_with_multimodal(
"Compare these performance metrics with the document content",
multimodal_content=[{
"type": "table",
"table_data": """Method,Accuracy,Speed
RAGAnything,95.2%,120ms
Traditional,87.3%,180ms""",
"table_caption": "Performance comparison"
}],
mode="hybrid"
)
# Query with equation content
equation_result = await rag.aquery_with_multimodal(
"Explain this formula and its relevance to the document content",
multimodal_content=[{
"type": "equation",
"latex": "P(d|q) = \\frac{P(q|d) \\cdot P(d)}{P(q)}",
"equation_caption": "Document relevance probability"
}],
mode="hybrid"
)
6. Loading Existing LightRAG Instance
import asyncio
from raganything import RAGAnything
from lightrag import LightRAG
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
import os
async def load_existing_lightrag():
# First, create or load an existing LightRAG instance
lightrag_working_dir = "./existing_lightrag_storage"
# Check if previous LightRAG instance exists
if os.path.exists(lightrag_working_dir) and os.listdir(lightrag_working_dir):
print("✅ Found existing LightRAG instance, loading...")
else:
print("❌ No existing LightRAG instance found, will create new one")
# Create/Load LightRAG instance with your configurations
lightrag_instance = LightRAG(
working_dir=lightrag_working_dir,
llm_model_func=lambda prompt, system_prompt=None, history_messages=[], **kwargs: openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key="your-api-key",
**kwargs,
),
embedding_func=EmbeddingFunc(
embedding_dim=3072,
max_token_size=8192,
func=lambda texts: openai_embed(
texts,
model="text-embedding-3-large",
api_key=api_key,
base_url=base_url,
),
)
)
# Initialize storage (this will load existing data if available)
await lightrag_instance.initialize_storages()
# Now initialize RAGAnything with the existing LightRAG instance
rag = RAGAnything(
lightrag=lightrag_instance, # Pass the existing LightRAG instance
# Only need vision model for multimodal processing
vision_model_func=lambda prompt, system_prompt=None, history_messages=[], image_data=None, **kwargs: openai_complete_if_cache(
"gpt-4o",
"",
system_prompt=None,
history_messages=[],
messages=[
{"role": "system", "content": system_prompt} if system_prompt else None,
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}
]} if image_data else {"role": "user", "content": prompt}
],
api_key="your-api-key",
**kwargs,
) if image_data else openai_complete_if_cache(
"gpt-4o-mini",
prompt,
system_prompt=system_prompt,
history_messages=history_messages,
api_key="your-api-key",
**kwargs,
)
# Note: working_dir, llm_model_func, embedding_func, etc. are inherited from lightrag_instance
)
# Query the existing knowledge base
result = await rag.query_with_multimodal(
"What data has been processed in this LightRAG instance?",
mode="hybrid"
)
print("Query result:", result)
# Add new multimodal documents to the existing LightRAG instance
await rag.process_document_complete(
file_path="path/to/new/multimodal_document.pdf",
output_dir="./output"
)
if __name__ == "__main__":
asyncio.run(load_existing_lightrag())
🛠️ Examples
Practical Implementation Demos

The examples/ directory contains comprehensive usage examples:
raganything_example.py: End-to-end document processing with MinerUmodalprocessors_example.py: Direct multimodal content processingoffice_document_test.py: Office document parsing test with MinerU (no API key required)image_format_test.py: Image format parsing test with MinerU (no API key required)text_format_test.py: Text format parsing test with MinerU (no API key required)
Run examples:
# End-to-end processing
python examples/raganything_example.py path/to/document.pdf --api-key YOUR_API_KEY
# Direct modal processing
python examples/modalprocessors_example.py --api-key YOUR_API_KEY
# Office document parsing test (MinerU only)
python examples/office_document_test.py --file path/to/document.docx
# Image format parsing test (MinerU only)
python examples/image_format_test.py --file path/to/image.bmp
# Text format parsing test (MinerU only)
python examples/text_format_test.py --file path/to/document.md
# Check LibreOffice installation
python examples/office_document_test.py --check-libreoffice --file dummy
# Check PIL/Pillow installation
python examples/image_format_test.py --check-pillow --file dummy
# Check ReportLab installation
python examples/text_format_test.py --check-reportlab --file dummy
🔧 Configuration
System Optimization Parameters
Environment Variables
Create a .env file (refer to .env.example):
OPENAI_API_KEY=your_openai_api_key
OPENAI_BASE_URL=your_base_url # Optional
Note: API keys are only required for full RAG processing with LLM integration. The parsing test files (
office_document_test.pyandimage_format_test.py) only test MinerU functionality and do not require API keys.
MinerU Configuration
MinerU 2.0 uses a simplified configuration approach:
# MinerU 2.0 uses command-line parameters instead of config files
# Check available options:
mineru --help
# Common configurations:
mineru -p input.pdf -o output_dir -m auto # Automatic parsing mode
mineru -p input.pdf -o output_dir -m ocr # OCR-focused parsing
mineru -p input.pdf -o output_dir -b pipeline --device cuda # GPU acceleration
You can also configure MinerU through RAGAnything parameters:
# Configure parsing behavior
await rag.process_document_complete(
file_path="document.pdf",
parse_method="auto", # or "ocr", "txt"
device="cuda", # GPU acceleration
backend="pipeline", # parsing backend
lang="en" # language optimization
)
Note: MinerU 2.0 no longer uses the
magic-pdf.jsonconfiguration file. All settings are now passed as command-line parameters or function arguments.
Processing Requirements
Different content types require specific optional dependencies:
- Office Documents (.doc, .docx, .ppt, .pptx, .xls, .xlsx): Install LibreOffice
- Extended Image Formats (.bmp, .tiff, .gif, .webp): Install with
pip install raganything[image] - Text Files (.txt, .md): Install with
pip install raganything[text]
📋 Quick Install: Use
pip install raganything[all]to enable all format support (Python dependencies only - LibreOffice still needs separate installation)
🧪 Supported Content Types
Document Formats
- PDFs - Research papers, reports, presentations
- Office Documents - DOC, DOCX, PPT, PPTX, XLS, XLSX
- Images - JPG, PNG, BMP, TIFF, GIF, WebP
- Text Files - TXT, MD
Multimodal Elements
- Images - Photographs, diagrams, charts, screenshots
- Tables - Data tables, comparison charts, statistical summaries
- Equations - Mathematical formulas in LaTeX format
- Generic Content - Custom content types via extensible processors
For installation of format-specific dependencies, see the Configuration section.
📖 Citation
Academic Reference
If you find RAG-Anything useful in your research, please cite our paper:
@article{guo2024lightrag,
title={LightRAG: Simple and Fast Retrieval-Augmented Generation},
author={Zirui Guo and Lianghao Xia and Yanhua Yu and Tu Ao and Chao Huang},
year={2024},
eprint={2410.05779},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
🔗 Related Projects
Ecosystem & Extensions
|
⚡
LightRAGSimple and Fast RAG |
🎥
VideoRAGExtreme Long-Context Video RAG |
✨
MiniRAGExtremely Simple RAG |
⭐ Star History
Community Growth Trajectory
🤝 Contribution
Join the Innovation
