You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
3.0 KiB
3.0 KiB
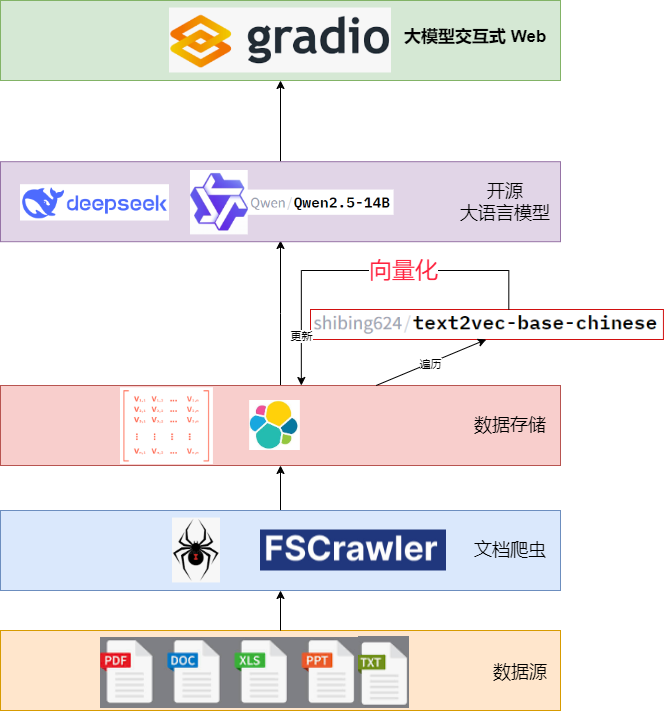
上述架构图展示了一个垂直的层次结构,描述了系统的核心组件及其连接关系,自上而下解读如下:
- Gradio Web 界面:
- 位于顶层,使用绿色矩形框表示,标注为"Gradio 大模型交互 Web"。这是用户与系统交互的入口,支持输入查询和接收回答。
- Qwen2.5-14b:
- 第二层,用紫色矩形框表示,包含 Qwen 的标志,以及"Qwen2.5-14B 开源大语言模型"字样。用户查询从 Gradio 传递至此,由 Qwen2.5-14b 处理。
- 注意咱们用的通义千问2.5的模型,实际也可以换成 DeepSeek 模型。
- 向量化层:
- 第三层,用红色矩形框表示,标注为"shibing624/text2vec-base-chinese 向量化"。此层将文本转化为向量,为后续的语义检索提供支持。
- Elasticsearch 搜索:
- 第四层,同样为红色矩形框,包含 Elasticsearch 标志和"搜索引擎"字样。向量化的数据在此存储并用于检索。
- FSCrawler 数据摄取:
- 第五层,用蓝色矩形框表示,标注为"FSCrawler 文档爬虫",负责将本地文档索引到 Elasticsearch。
- 数据源:
- 底层,用米色矩形框表示,包含 PDF、DOC、XLS、PPT、TXT 等文档类型图标,标注为"数据源"。
箭头从上到下连接各层,表明数据从用户界面流向大语言模型,再经过向量化、检索,最终基于文档数据生成回答。
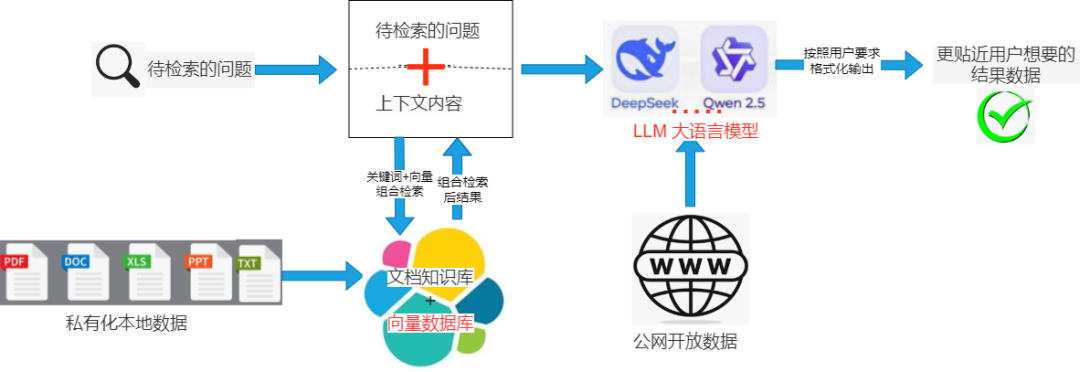
- 输入:
- 左侧标注为"待检索的问句",表示用户输入的查询。同时,"私有化本地数据源"(PDF、DOC、XLS 等)作为知识库基础。
- Elasticsearch:
- 中间核心组件,标注为"Elasticsearch",包含"向量数据库"和"向量检索"模块。查询和数据源均输入此模块,通过向量检索匹配相关文档。
- Qwen2.5 LLM:
- 右侧标注为"DeepSeek ... Qwen2.5 LLM 大语言模型",接收检索结果并生成回答。
- 输出与验证:
- 最终输出为"提取用户想要的精准答案",并通过"结果验证"确保准确性。此外,系统提供"公网开放接口",支持 API 访问。
3.3 综合分析
综合两图来看,系统采用经典的 RAG(Retrieval-Augmented Generation) 架构:
用户查询首先通过向量化模型(shibing624/text2vec-base-chinese)转化为向量,在 Elasticsearch 中检索相关文档,随后将查询与检索结果传递给 Qwen2.5-14b 生成最终回答。
Gradio 提供友好界面,FSCrawler 确保数据摄取的自动化,而公网接口则扩展了系统的应用场景。
检索增强生成(RAG)简单来说就是先从一大堆文档中找到跟用户问题相关的内容,然后用大语言模型把这些内容整理成自然、易懂的回答。