'commit'
This commit is contained in:
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 76 KiB |
@@ -1,30 +0,0 @@
|
||||
# 添加Anaconda的TUNA镜像
|
||||
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
|
||||
|
||||
# 设置搜索时显示通道地址
|
||||
conda config --set show_channel_urls yes
|
||||
|
||||
# 创建虚拟环境
|
||||
conda create -n rag python=3.10
|
||||
|
||||
# 查看当前存在哪些虚拟环境
|
||||
conda env list
|
||||
conda info -e
|
||||
|
||||
# 查看安装了哪些包
|
||||
conda list
|
||||
|
||||
# 激活虚拟环境
|
||||
conda activate rag
|
||||
|
||||
# 对虚拟环境中安装额外的包
|
||||
conda install -n rag $package_name
|
||||
|
||||
# 删除虚拟环境
|
||||
conda remove -n rag --all
|
||||
|
||||
# 删除环境中的某个包
|
||||
conda remove --name rag $package_name
|
||||
|
||||
# 恢复默认镜像
|
||||
conda config --remove-key channels
|
||||
@@ -1,16 +0,0 @@
|
||||
# 激活虚拟环境
|
||||
conda activate rag
|
||||
|
||||
# 永久修改pip源为阿里云镜像源(适用于Windows系统)
|
||||
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
|
||||
|
||||
# 验证是否修改成功
|
||||
pip config list
|
||||
|
||||
global.index-url='https://mirrors.aliyun.com/pypi/simple/'
|
||||
|
||||
# 获取依赖了哪些包
|
||||
pip freeze > requirements.txt
|
||||
|
||||
# 新机器安装包
|
||||
pip install -r D:\dsWork\dsProject\dsRag\requirements.txt
|
||||
@@ -1,132 +0,0 @@
|
||||
### 一、安装 $ES$
|
||||
|
||||
**1、下载安装包**
|
||||
|
||||
进入官网下载$linux$安装包 [下载地址](https://www.elastic.co/cn/downloads/elasticsearch)
|
||||
|
||||
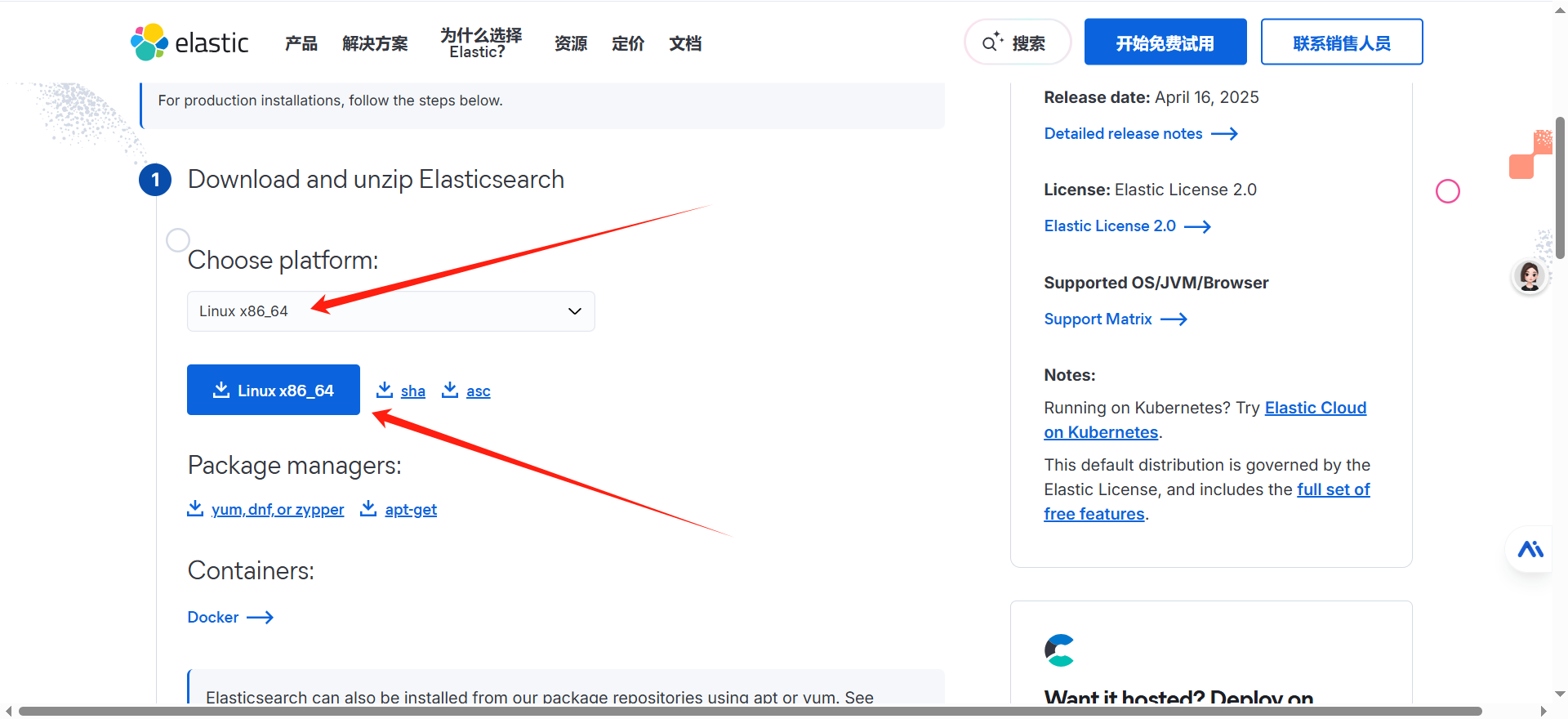
|
||||
|
||||
**2、安装$JDK$$21$**
|
||||
|
||||
```sh
|
||||
sudo yum install java-21-openjdk-devel
|
||||
echo 'export JAVA_HOME=/usr/lib/jvm/java-21-openjdk
|
||||
export PATH=$JAVA_HOME/bin:$PATH' >> ~/.bashrc
|
||||
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
**3、上传文件到$linux$服务器**
|
||||
|
||||
```sh
|
||||
# 如果没有 rz 命令 先安装
|
||||
yum -y install lrzsz
|
||||
|
||||
# rz 打开弹窗 选择下载好的文件 确认 在哪个目录下执行,就会上传到该目录下
|
||||
rz -be
|
||||
```
|
||||
|
||||
**4、新建用户并设置密码**
|
||||
|
||||
```sh
|
||||
# 创建用户
|
||||
useradd elauser
|
||||
|
||||
# 设置密码 符合密码规范 大写 + 小写 + 数字 + 特殊字符 + 大于八位
|
||||
passwd elauser
|
||||
|
||||
#输入密码:
|
||||
DsideaL@123
|
||||
|
||||
tar -zxvf elasticsearch-9.0.2-linux-x86_64.tar.gz
|
||||
sudo chown -R elauser:elauser /usr/local/elasticsearch-9.0.2
|
||||
# 进入解压文件并编辑配置文件
|
||||
cd elasticsearch-9.0.2/config
|
||||
vi elasticsearch.yml
|
||||
# 修改数据目录和日志目录
|
||||
mkdir -p /usr/local/elasticsearch-9.0.2/data
|
||||
mkdir -p /usr/local/elasticsearch-9.0.2/logs
|
||||
```
|
||||
|
||||
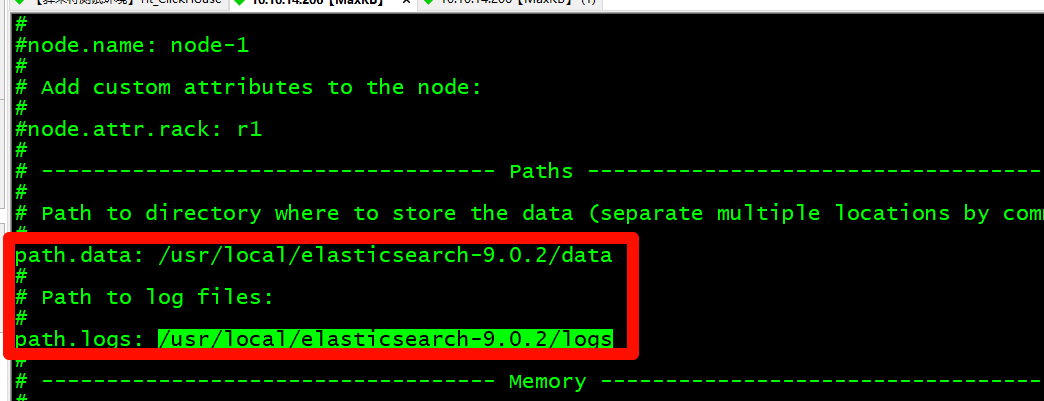
|
||||
|
||||
设置允许所有IP进行访问,在添加下面参数让$elasticsearch-head$插件可以访问$es$
|
||||
|
||||
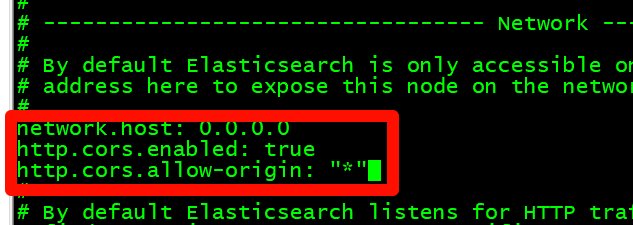
|
||||
|
||||
```yaml
|
||||
network.host: 0.0.0.0
|
||||
http.cors.enabled: true
|
||||
http.cors.allow-origin: "*"
|
||||
```
|
||||
|
||||
**5、修改系统配置**
|
||||
|
||||
```sh
|
||||
# m.max_map_count 值太低
|
||||
# 临时解决方案(需要root权限)
|
||||
sudo sysctl -w vm.max_map_count=262144
|
||||
|
||||
# 永久解决方案(需要root权限)
|
||||
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
|
||||
sudo sysctl -p
|
||||
|
||||
# 验证是否有效
|
||||
sysctl vm.max_map_count
|
||||
```
|
||||
|
||||
**6、启动**
|
||||
|
||||
```sh
|
||||
# 启动
|
||||
su - elauser
|
||||
|
||||
cd /usr/local/elasticsearch-9.0.2/bin
|
||||
# ./elasticsearch-keystore create
|
||||
|
||||
# 启动 -d = damon 守护进程
|
||||
./elasticsearch -d
|
||||
|
||||
|
||||
# 访问地址
|
||||
https://10.10.14.206:9200
|
||||
|
||||
# 日志文件
|
||||
/usr/local/elasticsearch-9.0.2/logs/elasticsearch.log
|
||||
```
|
||||
|
||||
弹出输入账号密码,这里需要重置下密码,再登录 进入安装目录的bin目录下
|
||||
|
||||
执行下面命令 就会在控制台打印出新密码 账号就是 elastic
|
||||
|
||||
```
|
||||
./elasticsearch-reset-password -u elastic
|
||||
```
|
||||
|
||||

|
||||
|
||||
登录成功,完活。
|
||||
|
||||
```sh
|
||||
elastic
|
||||
jv9h8uwRrRxmDi1dq6u8
|
||||
```
|
||||
|
||||
|
||||
|
||||
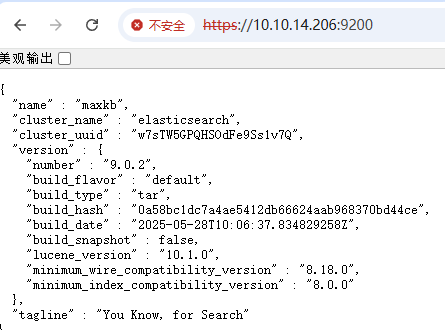
|
||||
|
||||
> **注意**:如果访问不到,请检查是否开启了$VPN$
|
||||
|
||||
### 二、安装$ik$中文分词插件
|
||||
|
||||
```bash
|
||||
# 安装分词插件
|
||||
./bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/9.0.2
|
||||
|
||||
# 检查插件列表
|
||||
[elauser@maxkb elasticsearch-9.0.2]$ ./bin/elasticsearch-plugin list
|
||||
analysis-ik
|
||||
```
|
||||
|
||||

|
||||
@@ -1,109 +0,0 @@
|
||||
import logging
|
||||
import warnings
|
||||
|
||||
from Config.Config import ES_CONFIG
|
||||
from Util.EsSearchUtil import EsSearchUtil
|
||||
|
||||
# 初始化日志
|
||||
logger = logging.getLogger(__name__)
|
||||
logger.setLevel(logging.INFO)
|
||||
|
||||
# 初始化EsSearchUtil
|
||||
esClient = EsSearchUtil(ES_CONFIG)
|
||||
# 抑制HTTPS相关警告
|
||||
warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
|
||||
warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 测试查询
|
||||
# query = "小学数学中有哪些模型"
|
||||
query = "文言虚词"
|
||||
query_tags = ["MATH_1"] # 默认搜索标签,可修改
|
||||
print(f"\n=== 开始执行查询 ===")
|
||||
print(f"原始查询文本: {query}")
|
||||
|
||||
# 执行混合搜索
|
||||
es_conn = esClient.es_pool.get_connection()
|
||||
try:
|
||||
# 向量搜索
|
||||
print("\n=== 向量搜索阶段 ===")
|
||||
print("1. 文本分词和向量化处理中...")
|
||||
query_embedding = esClient.text_to_embedding(query)
|
||||
print(f"2. 生成的查询向量维度: {len(query_embedding)}")
|
||||
print(f"3. 前3维向量值: {query_embedding[:3]}")
|
||||
|
||||
print("4. 正在执行Elasticsearch向量搜索...")
|
||||
vector_results = es_conn.search(
|
||||
index=ES_CONFIG['index_name'],
|
||||
body={
|
||||
"query": {
|
||||
"script_score": {
|
||||
"query": {
|
||||
"bool": {
|
||||
"should": [
|
||||
{
|
||||
"terms": {
|
||||
"tags.tags": query_tags
|
||||
}
|
||||
}
|
||||
],
|
||||
"minimum_should_match": 1
|
||||
}
|
||||
},
|
||||
"script": {
|
||||
"source": "double score = cosineSimilarity(params.query_vector, 'embedding'); return score >= 0 ? score : 0",
|
||||
"params": {"query_vector": query_embedding}
|
||||
}
|
||||
}
|
||||
},
|
||||
"size": 3
|
||||
}
|
||||
)
|
||||
print(f"5. 向量搜索结果数量: {len(vector_results['hits']['hits'])}")
|
||||
|
||||
# 文本精确搜索
|
||||
print("\n=== 文本精确搜索阶段 ===")
|
||||
print("1. 正在执行Elasticsearch文本精确搜索...")
|
||||
text_results = es_conn.search(
|
||||
index=ES_CONFIG['index_name'],
|
||||
body={
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [
|
||||
{
|
||||
"match": {
|
||||
"user_input": query
|
||||
}
|
||||
},
|
||||
{
|
||||
"terms": {
|
||||
"tags.tags": query_tags
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
},
|
||||
"size": 3
|
||||
}
|
||||
)
|
||||
print(f"2. 文本搜索结果数量: {len(text_results['hits']['hits'])}")
|
||||
|
||||
# 打印详细结果
|
||||
print("\n=== 最终搜索结果 ===")
|
||||
|
||||
vector_int = 0
|
||||
for i, hit in enumerate(vector_results['hits']['hits'], 1):
|
||||
if hit['_score'] > 0.4: # 阀值0.4
|
||||
print(f" {i}. 文档ID: {hit['_id']}, 相似度分数: {hit['_score']:.2f}")
|
||||
print(f" 内容: {hit['_source']['user_input']}")
|
||||
vector_int = vector_int + 1
|
||||
print(f" 向量搜索结果: {vector_int}条")
|
||||
|
||||
print("\n文本精确搜索结果:")
|
||||
for i, hit in enumerate(text_results['hits']['hits']):
|
||||
print(f" {i + 1}. 文档ID: {hit['_id']}, 匹配分数: {hit['_score']:.2f}")
|
||||
print(f" 内容: {hit['_source']['user_input']}")
|
||||
# print(f" 详细: {hit['_source']['tags']['full_content']}")
|
||||
|
||||
finally:
|
||||
esClient.es_pool.release_connection(es_conn)
|
||||
209
dsSchoolBuddy/ElasticSearch/T7_XiangLiangQuery.py
Normal file
209
dsSchoolBuddy/ElasticSearch/T7_XiangLiangQuery.py
Normal file
@@ -0,0 +1,209 @@
|
||||
import logging
|
||||
import warnings
|
||||
import json
|
||||
import requests
|
||||
from typing import List, Tuple, Dict
|
||||
|
||||
from elasticsearch import Elasticsearch
|
||||
|
||||
from Config import Config
|
||||
from Config.Config import ES_CONFIG, EMBED_MODEL_NAME, EMBED_BASE_URL, EMBED_API_KEY, RERANK_MODEL, RERANK_BASE_URL, RERANK_BINDING_API_KEY
|
||||
from langchain_openai import OpenAIEmbeddings
|
||||
from pydantic import SecretStr
|
||||
|
||||
# 初始化日志
|
||||
logger = logging.getLogger(__name__)
|
||||
logger.setLevel(logging.INFO)
|
||||
|
||||
# 抑制HTTPS相关警告
|
||||
warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
|
||||
warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
|
||||
|
||||
|
||||
def text_to_embedding(text: str) -> List[float]:
|
||||
"""
|
||||
将文本转换为嵌入向量
|
||||
"""
|
||||
embeddings = OpenAIEmbeddings(
|
||||
model=EMBED_MODEL_NAME,
|
||||
base_url=EMBED_BASE_URL,
|
||||
api_key=SecretStr(EMBED_API_KEY)
|
||||
)
|
||||
return embeddings.embed_query(text)
|
||||
|
||||
|
||||
def rerank_results(query: str, results: List[Dict]) -> List[Tuple[Dict, float]]:
|
||||
"""
|
||||
对搜索结果进行重排
|
||||
"""
|
||||
if len(results) <= 1:
|
||||
return [(doc, 1.0) for doc in results]
|
||||
|
||||
# 准备重排请求数据
|
||||
rerank_data = {
|
||||
"model": RERANK_MODEL,
|
||||
"query": query,
|
||||
"documents": [doc['_source']['user_input'] for doc in results],
|
||||
"top_n": len(results)
|
||||
}
|
||||
|
||||
# 调用SiliconFlow API进行重排
|
||||
headers = {
|
||||
"Content-Type": "application/json",
|
||||
"Authorization": f"Bearer {RERANK_BINDING_API_KEY}"
|
||||
}
|
||||
|
||||
try:
|
||||
response = requests.post(RERANK_BASE_URL, headers=headers, data=json.dumps(rerank_data))
|
||||
response.raise_for_status()
|
||||
rerank_result = response.json()
|
||||
|
||||
# 处理重排结果
|
||||
reranked_docs_with_scores = []
|
||||
if "results" in rerank_result:
|
||||
for item in rerank_result["results"]:
|
||||
doc_idx = item.get("index")
|
||||
score = item.get("relevance_score", 0.0)
|
||||
if 0 <= doc_idx < len(results):
|
||||
reranked_docs_with_scores.append((results[doc_idx], score))
|
||||
return reranked_docs_with_scores
|
||||
except Exception as e:
|
||||
logger.error(f"重排失败: {str(e)}")
|
||||
return [(doc, 1.0) for doc in results]
|
||||
|
||||
|
||||
def merge_results(keyword_results: List[Tuple[Dict, float]], vector_results: List[Tuple[Dict, float]]) -> List[Tuple[Dict, float, str]]:
|
||||
"""
|
||||
合并关键字搜索和向量搜索结果
|
||||
"""
|
||||
# 标记结果来源并合并
|
||||
all_results = []
|
||||
for doc, score in keyword_results:
|
||||
all_results.append((doc, score, "关键字搜索"))
|
||||
for doc, score in vector_results:
|
||||
all_results.append((doc, score, "向量搜索"))
|
||||
|
||||
# 去重并按分数排序
|
||||
unique_results = {}
|
||||
for doc, score, source in all_results:
|
||||
doc_id = doc['_id']
|
||||
if doc_id not in unique_results or score > unique_results[doc_id][1]:
|
||||
unique_results[doc_id] = (doc, score, source)
|
||||
|
||||
# 按分数降序排序
|
||||
sorted_results = sorted(unique_results.values(), key=lambda x: x[1], reverse=True)
|
||||
return sorted_results
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 初始化EsSearchUtil
|
||||
esClient = Elasticsearch(
|
||||
hosts=Config.ES_CONFIG['hosts'],
|
||||
basic_auth=Config.ES_CONFIG['basic_auth'],
|
||||
verify_certs=False
|
||||
)
|
||||
|
||||
# 获取用户输入
|
||||
user_query = input("请输入查询语句(例如:高性能的混凝土): ")
|
||||
if not user_query:
|
||||
user_query = "高性能的混凝土"
|
||||
print(f"未输入查询语句,使用默认值: {user_query}")
|
||||
|
||||
query_tags = [] # 可以根据需要添加标签过滤
|
||||
|
||||
print(f"\n=== 开始执行查询 ===")
|
||||
print(f"原始查询文本: {user_query}")
|
||||
|
||||
# 执行搜索
|
||||
es_conn = esClient.es_pool.get_connection()
|
||||
try:
|
||||
# 1. 向量搜索
|
||||
print("\n=== 向量搜索阶段 ===")
|
||||
print("1. 文本向量化处理中...")
|
||||
query_embedding = text_to_embedding(user_query)
|
||||
print(f"2. 生成的查询向量维度: {len(query_embedding)}")
|
||||
print(f"3. 前3维向量值: {query_embedding[:3]}")
|
||||
|
||||
print("4. 正在执行Elasticsearch向量搜索...")
|
||||
vector_results = es_conn.search(
|
||||
index=ES_CONFIG['index_name'],
|
||||
body={
|
||||
"query": {
|
||||
"script_score": {
|
||||
"query": {
|
||||
"bool": {
|
||||
"should": [
|
||||
{
|
||||
"terms": {
|
||||
"tags.tags": query_tags
|
||||
}
|
||||
}
|
||||
] if query_tags else {"match_all": {}},
|
||||
"minimum_should_match": 1 if query_tags else 0
|
||||
}
|
||||
},
|
||||
"script": {
|
||||
"source": "double score = cosineSimilarity(params.query_vector, 'embedding'); return score >= 0 ? score : 0",
|
||||
"params": {"query_vector": query_embedding}
|
||||
}
|
||||
}
|
||||
},
|
||||
"size": 5
|
||||
}
|
||||
)
|
||||
vector_hits = vector_results['hits']['hits']
|
||||
print(f"5. 向量搜索结果数量: {len(vector_hits)}")
|
||||
|
||||
# 向量结果重排
|
||||
print("6. 正在进行向量结果重排...")
|
||||
reranked_vector_results = rerank_results(user_query, vector_hits)
|
||||
print(f"7. 重排后向量结果数量: {len(reranked_vector_results)}")
|
||||
|
||||
# 2. 关键字搜索
|
||||
print("\n=== 关键字搜索阶段 ===")
|
||||
print("1. 正在执行Elasticsearch关键字搜索...")
|
||||
keyword_results = es_conn.search(
|
||||
index=ES_CONFIG['index_name'],
|
||||
body={
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [
|
||||
{
|
||||
"match": {
|
||||
"user_input": user_query
|
||||
}
|
||||
}
|
||||
] + ([
|
||||
{
|
||||
"terms": {
|
||||
"tags.tags": query_tags
|
||||
}
|
||||
}
|
||||
] if query_tags else [])
|
||||
}
|
||||
},
|
||||
"size": 5
|
||||
}
|
||||
)
|
||||
keyword_hits = keyword_results['hits']['hits']
|
||||
print(f"2. 关键字搜索结果数量: {len(keyword_hits)}")
|
||||
|
||||
# 3. 合并结果
|
||||
print("\n=== 合并搜索结果 ===")
|
||||
# 为关键字结果添加默认分数1.0
|
||||
keyword_results_with_scores = [(doc, doc['_score']) for doc in keyword_hits]
|
||||
merged_results = merge_results(keyword_results_with_scores, reranked_vector_results)
|
||||
print(f"合并后唯一结果数量: {len(merged_results)}")
|
||||
|
||||
# 4. 打印最终结果
|
||||
print("\n=== 最终搜索结果 ===")
|
||||
for i, (doc, score, source) in enumerate(merged_results, 1):
|
||||
print(f"{i}. 文档ID: {doc['_id']}, 分数: {score:.2f}, 来源: {source}")
|
||||
print(f" 内容: {doc['_source']['user_input']}")
|
||||
print(" --- ")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"搜索过程中发生错误: {str(e)}")
|
||||
print(f"搜索失败: {str(e)}")
|
||||
finally:
|
||||
esClient.es_pool.release_connection(es_conn)
|
||||
Reference in New Issue
Block a user