|
|
|
|
@ -1 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
**向量化模型**:
|
|
|
|
|
|
|
|
|
|
- SentenceModel('shibing624/text2vec-base-chinese'),专为中文文本设计的句子嵌入模型,用于将查询和文档转化为向量表示。
|
|
|
|
|
|
|
|
|
|
```sh
|
|
|
|
|
# 下载地址
|
|
|
|
|
https://huggingface.co/shibing624/text2vec-base-chinese
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
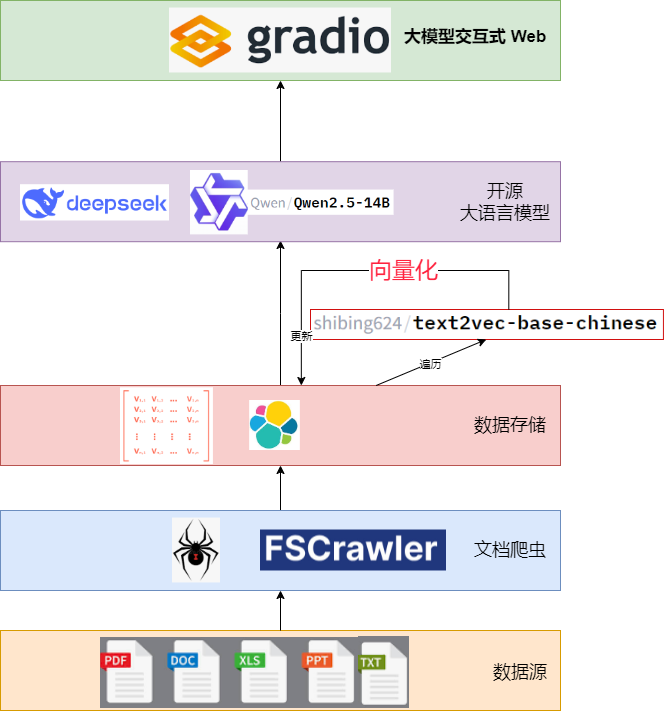
上述架构图展示了一个垂直的层次结构,描述了系统的核心组件及其连接关系,自上而下解读如下:
|
|
|
|
|
|
|
|
|
|
- **Gradio Web 界面**:
|
|
|
|
|
- 位于顶层,使用绿色矩形框表示,标注为"Gradio 大模型交互 Web"。这是用户与系统交互的入口,支持输入查询和接收回答。
|
|
|
|
|
- **Qwen2.5-14b**:
|
|
|
|
|
- 第二层,用紫色矩形框表示,包含 Qwen 的标志,以及"Qwen2.5-14B 开源大语言模型"字样。用户查询从 Gradio 传递至此,由 Qwen2.5-14b 处理。
|
|
|
|
|
- 注意咱们用的通义千问2.5的模型,实际也可以换成 DeepSeek 模型。
|
|
|
|
|
- **向量化层**:
|
|
|
|
|
- 第三层,用红色矩形框表示,标注为"shibing624/text2vec-base-chinese 向量化"。此层将文本转化为向量,为后续的语义检索提供支持。
|
|
|
|
|
- **Elasticsearch 搜索**:
|
|
|
|
|
- 第四层,同样为红色矩形框,包含 Elasticsearch 标志和"搜索引擎"字样。向量化的数据在此存储并用于检索。
|
|
|
|
|
- **FSCrawler 数据摄取**:
|
|
|
|
|
- 第五层,用蓝色矩形框表示,标注为"FSCrawler 文档爬虫",负责将本地文档索引到 Elasticsearch。
|
|
|
|
|
- **数据源**:
|
|
|
|
|
- 底层,用米色矩形框表示,包含 PDF、DOC、XLS、PPT、TXT 等文档类型图标,标注为"数据源"。
|
|
|
|
|
|
|
|
|
|
箭头从上到下连接各层,表明数据从用户界面流向大语言模型,再经过向量化、检索,最终基于文档数据生成回答。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
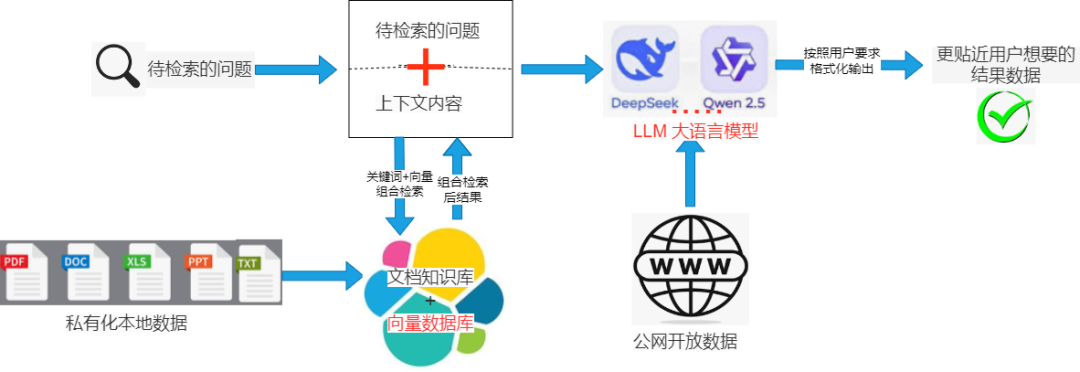
- **输入**:
|
|
|
|
|
- 左侧标注为"待检索的问句",表示用户输入的查询。同时,"私有化本地数据源"(PDF、DOC、XLS 等)作为知识库基础。
|
|
|
|
|
- **Elasticsearch**:
|
|
|
|
|
- 中间核心组件,标注为"Elasticsearch",包含"向量数据库"和"向量检索"模块。查询和数据源均输入此模块,通过向量检索匹配相关文档。
|
|
|
|
|
- **Qwen2.5 LLM**:
|
|
|
|
|
- 右侧标注为"DeepSeek ... Qwen2.5 LLM 大语言模型",接收检索结果并生成回答。
|
|
|
|
|
- **输出与验证**:
|
|
|
|
|
- 最终输出为"提取用户想要的精准答案",并通过"结果验证"确保准确性。此外,系统提供"公网开放接口",支持 API 访问。
|
|
|
|
|
|
|
|
|
|
#### 3.3 综合分析
|
|
|
|
|
|
|
|
|
|
综合两图来看,系统采用经典的 **RAG(Retrieval-Augmented Generation)** 架构:
|
|
|
|
|
|
|
|
|
|
用户查询首先通过向量化模型(`shibing624/text2vec-base-chinese`)转化为向量,在 Elasticsearch 中检索相关文档,随后将查询与检索结果传递给 Qwen2.5-14b 生成最终回答。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Gradio 提供友好界面,FSCrawler 确保数据摄取的自动化,而公网接口则扩展了系统的应用场景。
|
|
|
|
|
|
|
|
|
|
检索增强生成(RAG)简单来说就是**先从一大堆文档中找到跟用户问题相关的内容,然后用大语言模型把这些内容整理成自然、易懂的回答**。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### 4. 知识库智能问答系统代码解读
|
|
|
|
|
|
|
|
|
|
以下是实现该系统的一般步骤与代码思路,具体代码放到[死磕Elasticsearch知识星球](https://jishuzhan.net/article/1898217914180947969)。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 4.1 文档摄取
|
|
|
|
|
|
|
|
|
|
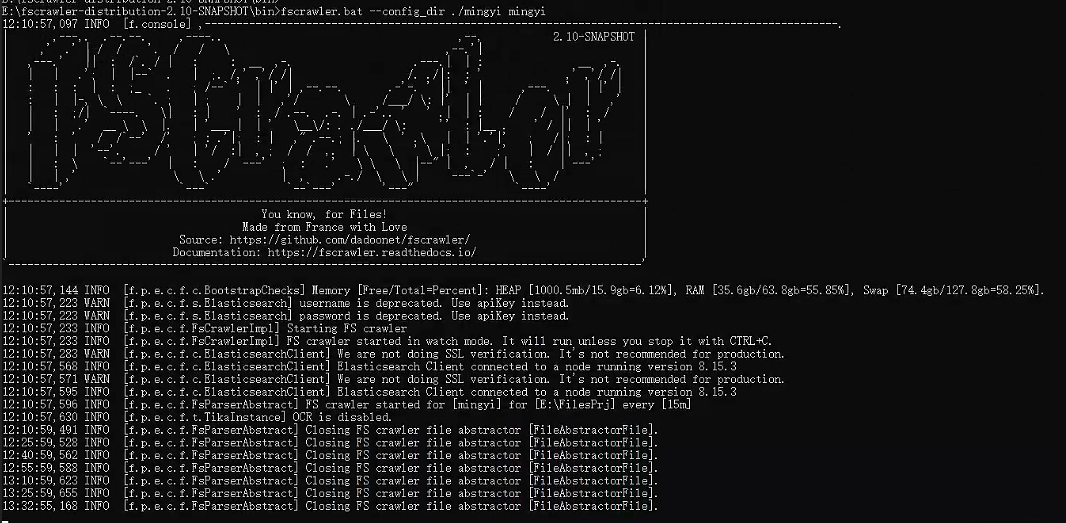
使用 FSCrawler 扫描本地文件并索引到 Elasticsearch:
|
|
|
|
|
|
|
|
|
|
```sh
|
|
|
|
|
fscrawler --config_dir /path/to/config job_name
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
配置文件需指定文档路径和 Elasticsearch 索引名称。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 4.2 向量化
|
|
|
|
|
|
|
|
|
|
利用 `shibing624/text2vec-base-chinese` 对文档和查询进行[向量化](https://jishuzhan.net/article/1898217914180947969):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
from text2vec import SentenceModel
|
|
|
|
|
model = SentenceModel('shibing624/text2vec-base-chinese')
|
|
|
|
|
|
|
|
|
|
# 文档向量化并存入 Elasticsearch
|
|
|
|
|
for doc in documents:
|
|
|
|
|
vector = model.encode(doc['text'])
|
|
|
|
|
es.index(index='knowledge_base', body={'text': doc['text'], 'vector': vector})
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
#### 4.3 查询处理与检索
|
|
|
|
|
|
|
|
|
|
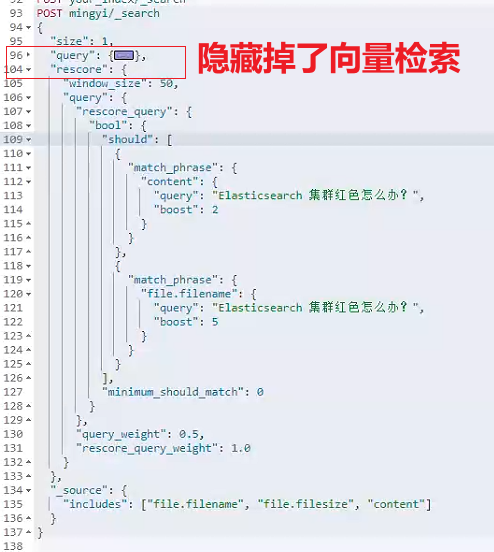
将用户查询向量化并在 Elasticsearch 中执行相似性搜索,这里本质做的是关键词匹配+向量检索的组合方式。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
#### 4.4 回答生成
|
|
|
|
|
|
|
|
|
|
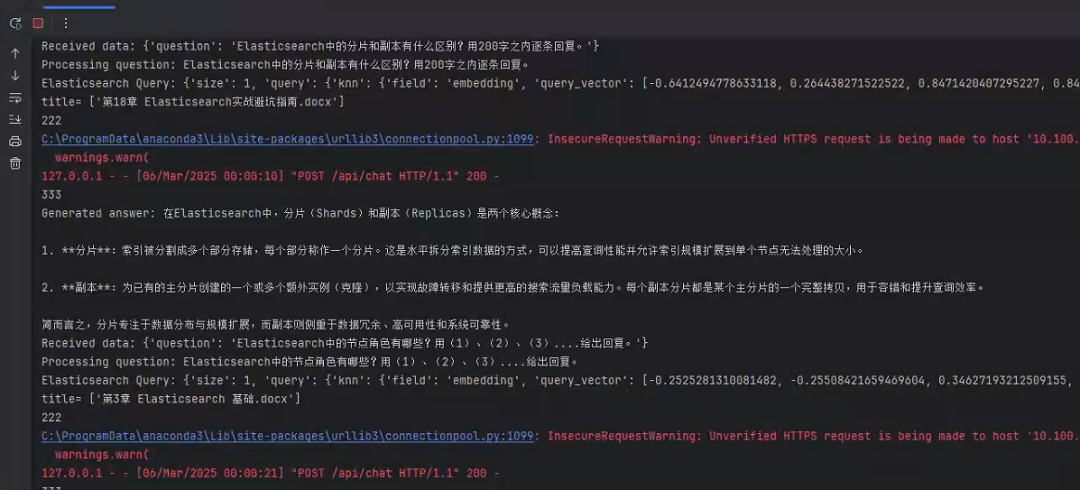
将查询和检索结果传递给 Qwen2.5-14b 生成回答:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
from ollama import Client
|
|
|
|
|
ollama = Client()
|
|
|
|
|
context = "\n".join([doc['_source']['text'] for doc in results['hits']['hits']])
|
|
|
|
|
prompt = f"根据以下内容回答问题:\n{context}\n问题:{query}"
|
|
|
|
|
response = ollama.generate(model='qwen2.5:14b', prompt=prompt)
|
|
|
|
|
answer = response['text']
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
#### 4.5 Gradio 界面
|
|
|
|
|
|
|
|
|
|
通过 Gradio 实现交互:
|
|
|
|
|
|
|
|
|
|
```python
|
|
|
|
|
import gradio as gr
|
|
|
|
|
def qa_system(query):
|
|
|
|
|
# 查询处理、检索、生成逻辑
|
|
|
|
|
return answer
|
|
|
|
|
interface = gr.Interface(fn=qa_system, inputs="text", outputs="text")
|
|
|
|
|
interface.launch()
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
上述步骤展示了从数据摄取到回答生成的完整流程,体现了系统的模块化设计。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
### 5. 知识库智能问答系统待改进和展望
|
|
|
|
|
|
|
|
|
|
为进一步提升系统性能与用户体验,可考虑以下改进方向:
|
|
|
|
|
|
|
|
|
|
- **模型优化**:
|
|
|
|
|
- 对 Qwen2.5-14b 进行领域特定微调,提升对知识库内容的理解能力。
|
|
|
|
|
- 换成 DeepSeek 模型做对比。
|
|
|
|
|
- **向量化改进**:
|
|
|
|
|
- 尝试其他中文嵌入模型或微调 `text2vec`,提高向量表示的语义准确性。
|
|
|
|
|
- **文章切分力度**:
|
|
|
|
|
- 当前大家看到一章内容一个文档,效果可以。
|
|
|
|
|
- 但如果更细化为一小节内容一个文档导入 Elasticsearch,是不是更好呢?都有待进一步验证!
|
|
|
|
|
|
|
|
|
|
------
|
|
|
|
|
|
|
|
|
|
### 结语
|
|
|
|
|
|
|
|
|
|
基于 Qwen2.5-14b 与 Elasticsearch 的大数据知识库智能问答系统,通过向量检索与生成式 AI 的检索增强 RAG 结合,为用户提供了高效、精准的信息获取途径。
|
|
|
|
|
|
|
|
|
|
无论是技术架构的清晰性,还是实测效果的可靠性,该系统都展现了检索增强RAG 在知识管理领域的巨大潜力。
|
|
|
|
|
|
|
|
|
|
视频讲解地址:https://t.zsxq.com/E1toS
|
|
|
|
|
|