diff --git a/dsLightRag/Test/G2_TeachingStudent.py b/dsLightRag/Test/G2_TeachingStudent.py
index c819af6c..8470248c 100644
--- a/dsLightRag/Test/G2_TeachingStudent.py
+++ b/dsLightRag/Test/G2_TeachingStudent.py
@@ -3,45 +3,39 @@ import sys
from Util import LlmUtil
-def initialize_chat_history():
- """初始化对话历史,包含系统提示"""
- system_prompt = """
- STRICT RULES
-Be an approachable-yet-dynamic teacher,who helps the user learn by guiding
-them through their studies.
-
-1.Get to know the user.lf you don't know their goals or grade level,ask the
-user before diving in.(Keep this lightweight!)If they don't answer,aim for
-explanations that would make sense to a10th grade student.
-
-2.Build on existing knowledge.Connect new ideas to what the user already
-knows.
-
-3.Guide users,don't just give answers.Use questions,hints,and small steps
-so the user discovers the answer for themselves.
-
-4.Check and reinforce.After hard parts,confirm the user can restate or use the
-idea.Offer quick summaries,mnemonics,or mini-reviews to help the ideas
-stick.
-
-5.Vary the rhythm.Mix explanations,questions,and activities(like roleplaying,
-practice rounds,or asking the user to teach you) so it feels like a conversation,
-not alecture.
-
-Above all:DO NOT DO THE USER'S WORK FOR THEM. Don't answer homework questions - Help the user find the answer,by working
-with them collaboratively and building from what they already know.
+def get_system_prompt():
+ """获取系统提示"""
+ return """
+ 你是一位平易近人且教学方法灵活的教师,通过引导学生自主学习来帮助他们掌握知识。
+
+ 严格遵循以下教学规则:
+ 1. 首先了解学生情况:在开始讲解前,询问学生的年级水平和对勾股定理的了解程度。
+ 2. 基于现有知识构建:将新思想与学生已有的知识联系起来。
+ 3. 引导而非灌输:使用问题、提示和小步骤,让学生自己发现答案。
+ 4. 检查和强化:在讲解难点后,确认学生能够重述或应用这些概念。
+ 5. 变化节奏:混合讲解、提问和互动活动,让教学像对话而非讲座。
+
+ 最重要的是:不要直接给出答案,而是通过合作和基于学生已有知识的引导,帮助学生自己找到答案。
"""
- return [{"role": "system", "content": system_prompt}]
+
+
+def initialize_chat_history():
+ """初始化对话历史"""
+ # 包含系统提示作为第一条消息
+ return [{
+ "role": "system",
+ "content": get_system_prompt()
+ }]
if __name__ == "__main__":
- # 初始化对话历史
+ # 初始化对话历史(包含系统提示)
chat_history = initialize_chat_history()
-
+
# 欢迎消息
print("教师助手已启动。输入 'exit' 或 '退出' 结束对话。")
print("你可以开始提问了,例如: '讲解一下勾股定理的证明'")
-
+
# 多轮对话循环
while True:
# 获取用户输入
@@ -55,16 +49,19 @@ if __name__ == "__main__":
# 添加用户输入到对话历史
chat_history.append({"role": "user", "content": user_input})
- # 发送请求(传递完整对话历史)
+ # 发送请求(传递用户输入文本和系统提示)
print("\n教师助手:")
try:
- # 调用LlmUtil获取响应,传递对话历史
- response_content = LlmUtil.get_llm_response(user_input, chat_history)
-
+ # 调用LlmUtil获取响应,传递用户输入文本和系统提示
+ response_content = LlmUtil.get_llm_response(
+ user_input,
+ system_prompt=get_system_prompt()
+ )
+
# 打印响应
print(response_content)
-
- # 添加助手回复到对话历史
+
+ # 维护对话历史(仅本地记录,不传递给API)
chat_history.append({"role": "assistant", "content": response_content})
except Exception as e:
print(f"发生错误: {str(e)}")
diff --git a/dsLightRag/Util/LlmUtil.py b/dsLightRag/Util/LlmUtil.py
index 12db6a5c..e00c2a87 100644
--- a/dsLightRag/Util/LlmUtil.py
+++ b/dsLightRag/Util/LlmUtil.py
@@ -54,11 +54,12 @@ async def get_llm_response_async(query_text: str, stream: bool = True):
yield f"处理请求时发生异常: {str(e)}"
# 保留原同步函数
-def get_llm_response(query_text: str, stream: bool = True):
+def get_llm_response(query_text: str, stream: bool = True, system_prompt: str = 'You are a helpful assistant.'):
"""
获取大模型的响应
@param query_text: 查询文本
@param stream: 是否使用流式输出
+ @param system_prompt: 系统提示文本,默认为'You are a helpful assistant.'
@return: 完整响应文本
"""
client = OpenAI(
@@ -70,7 +71,7 @@ def get_llm_response(query_text: str, stream: bool = True):
completion = client.chat.completions.create(
model=LLM_MODEL_NAME,
messages=[
- {'role': 'system', 'content': 'You are a helpful assistant.'},
+ {'role': 'system', 'content': system_prompt},
{'role': 'user', 'content': query_text}
],
stream=stream
diff --git a/dsLightRag/Util/__pycache__/LlmUtil.cpython-310.pyc b/dsLightRag/Util/__pycache__/LlmUtil.cpython-310.pyc
index 1ddb25a0..bd138d45 100644
Binary files a/dsLightRag/Util/__pycache__/LlmUtil.cpython-310.pyc and b/dsLightRag/Util/__pycache__/LlmUtil.cpython-310.pyc differ
diff --git a/dsRag/.idea/RAG.iml b/dsRag/.idea/RAG.iml
index f1d90d5d..2ef181ef 100644
--- a/dsRag/.idea/RAG.iml
+++ b/dsRag/.idea/RAG.iml
@@ -4,7 +4,7 @@
-
+
diff --git a/dsRag/.idea/misc.xml b/dsRag/.idea/misc.xml
index 913c162f..4ccb922a 100644
--- a/dsRag/.idea/misc.xml
+++ b/dsRag/.idea/misc.xml
@@ -3,5 +3,5 @@
-
+
\ No newline at end of file
diff --git a/dsSchoolBuddy/.idea/.gitignore b/dsSchoolBuddy/.idea/.gitignore
new file mode 100644
index 00000000..a7cdac76
--- /dev/null
+++ b/dsSchoolBuddy/.idea/.gitignore
@@ -0,0 +1,8 @@
+# 默认忽略的文件
+/shelf/
+/workspace.xml
+# 基于编辑器的 HTTP 客户端请求
+/httpRequests/
+# Datasource local storage ignored files
+/dataSources/
+/dataSources.local.xml
diff --git a/dsSchoolBuddy/.idea/RAG.iml b/dsSchoolBuddy/.idea/RAG.iml
new file mode 100644
index 00000000..2ef181ef
--- /dev/null
+++ b/dsSchoolBuddy/.idea/RAG.iml
@@ -0,0 +1,12 @@
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/dsSchoolBuddy/.idea/inspectionProfiles/profiles_settings.xml b/dsSchoolBuddy/.idea/inspectionProfiles/profiles_settings.xml
new file mode 100644
index 00000000..105ce2da
--- /dev/null
+++ b/dsSchoolBuddy/.idea/inspectionProfiles/profiles_settings.xml
@@ -0,0 +1,6 @@
+
+
+
+
+
+
\ No newline at end of file
diff --git a/dsSchoolBuddy/.idea/jsLibraryMappings.xml b/dsSchoolBuddy/.idea/jsLibraryMappings.xml
new file mode 100644
index 00000000..1bde7079
--- /dev/null
+++ b/dsSchoolBuddy/.idea/jsLibraryMappings.xml
@@ -0,0 +1,6 @@
+
+
+
+
+
+
\ No newline at end of file
diff --git a/dsSchoolBuddy/.idea/misc.xml b/dsSchoolBuddy/.idea/misc.xml
new file mode 100644
index 00000000..4ccb922a
--- /dev/null
+++ b/dsSchoolBuddy/.idea/misc.xml
@@ -0,0 +1,7 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/dsSchoolBuddy/.idea/modules.xml b/dsSchoolBuddy/.idea/modules.xml
new file mode 100644
index 00000000..23b163c9
--- /dev/null
+++ b/dsSchoolBuddy/.idea/modules.xml
@@ -0,0 +1,8 @@
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/dsSchoolBuddy/.idea/vcs.xml b/dsSchoolBuddy/.idea/vcs.xml
new file mode 100644
index 00000000..61aaccdb
--- /dev/null
+++ b/dsSchoolBuddy/.idea/vcs.xml
@@ -0,0 +1,7 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/dsSchoolBuddy/Config/Config.py b/dsSchoolBuddy/Config/Config.py
new file mode 100644
index 00000000..94344ebc
--- /dev/null
+++ b/dsSchoolBuddy/Config/Config.py
@@ -0,0 +1,27 @@
+# Elasticsearch配置
+ES_CONFIG = {
+ "hosts": "https://127.0.0.1:9200",
+ "basic_auth": ("elastic", "jv9h8uwRrRxmDi1dq6u8"),
+ "verify_certs": False,
+ "ssl_show_warn": False,
+ "index_name": "ds_kb"
+}
+
+# 嵌入向量模型
+EMBED_MODEL_NAME = "BAAI/bge-m3"
+EMBED_API_KEY = "sk-pbqibyjwhrgmnlsmdygplahextfaclgnedetybccknxojlyl"
+EMBED_BASE_URL = "https://api.siliconflow.cn/v1"
+EMBED_DIM = 1024
+EMBED_MAX_TOKEN_SIZE = 8192
+
+# 重排模型
+RERANK_MODEL = 'BAAI/bge-reranker-v2-m3'
+RERANK_BASE_URL = 'https://api.siliconflow.cn/v1/rerank'
+RERANK_BINDING_API_KEY = 'sk-pbqibyjwhrgmnlsmdygplahextfaclgnedetybccknxojlyl'
+
+# 阿里云API信息【HZKJ】
+ALY_LLM_API_KEY = "sk-01d13a39e09844038322108ecdbd1bbc"
+ALY_LLM_BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
+ALY_LLM_MODEL_NAME = "qwen-plus"
+#ALY_LLM_MODEL_NAME = "deepseek-r1"
+# ALY_LLM_MODEL_NAME = "deepseek-v3"
\ No newline at end of file
diff --git a/dsSchoolBuddy/Config/__init__.py b/dsSchoolBuddy/Config/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/dsSchoolBuddy/Config/__pycache__/Config.cpython-310.pyc b/dsSchoolBuddy/Config/__pycache__/Config.cpython-310.pyc
new file mode 100644
index 00000000..82eb2f5e
Binary files /dev/null and b/dsSchoolBuddy/Config/__pycache__/Config.cpython-310.pyc differ
diff --git a/dsSchoolBuddy/Config/__pycache__/__init__.cpython-310.pyc b/dsSchoolBuddy/Config/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 00000000..b3f99ca7
Binary files /dev/null and b/dsSchoolBuddy/Config/__pycache__/__init__.cpython-310.pyc differ
diff --git a/dsSchoolBuddy/Doc/1、python环境配置.png b/dsSchoolBuddy/Doc/1、python环境配置.png
new file mode 100644
index 00000000..ffc55842
Binary files /dev/null and b/dsSchoolBuddy/Doc/1、python环境配置.png differ
diff --git a/dsSchoolBuddy/Doc/2、Conda维护.txt b/dsSchoolBuddy/Doc/2、Conda维护.txt
new file mode 100644
index 00000000..021764bf
--- /dev/null
+++ b/dsSchoolBuddy/Doc/2、Conda维护.txt
@@ -0,0 +1,30 @@
+# 添加Anaconda的TUNA镜像
+conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
+
+# 设置搜索时显示通道地址
+conda config --set show_channel_urls yes
+
+# 创建虚拟环境
+conda create -n rag python=3.10
+
+# 查看当前存在哪些虚拟环境
+conda env list
+conda info -e
+
+# 查看安装了哪些包
+conda list
+
+# 激活虚拟环境
+conda activate rag
+
+# 对虚拟环境中安装额外的包
+conda install -n rag $package_name
+
+# 删除虚拟环境
+conda remove -n rag --all
+
+# 删除环境中的某个包
+conda remove --name rag $package_name
+
+# 恢复默认镜像
+conda config --remove-key channels
diff --git a/dsSchoolBuddy/Doc/3、Pip维护.txt b/dsSchoolBuddy/Doc/3、Pip维护.txt
new file mode 100644
index 00000000..081e047b
--- /dev/null
+++ b/dsSchoolBuddy/Doc/3、Pip维护.txt
@@ -0,0 +1,16 @@
+# 激活虚拟环境
+conda activate rag
+
+# 永久修改pip源为阿里云镜像源(适用于Windows系统)
+pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
+
+# 验证是否修改成功
+pip config list
+
+global.index-url='https://mirrors.aliyun.com/pypi/simple/'
+
+# 获取依赖了哪些包
+pip freeze > requirements.txt
+
+# 新机器安装包
+pip install -r D:\dsWork\dsProject\dsRag\requirements.txt
\ No newline at end of file
diff --git a/dsSchoolBuddy/Doc/4、Elasticsearch安装配置文档.md b/dsSchoolBuddy/Doc/4、Elasticsearch安装配置文档.md
new file mode 100644
index 00000000..cac6d013
--- /dev/null
+++ b/dsSchoolBuddy/Doc/4、Elasticsearch安装配置文档.md
@@ -0,0 +1,132 @@
+### 一、安装 $ES$
+
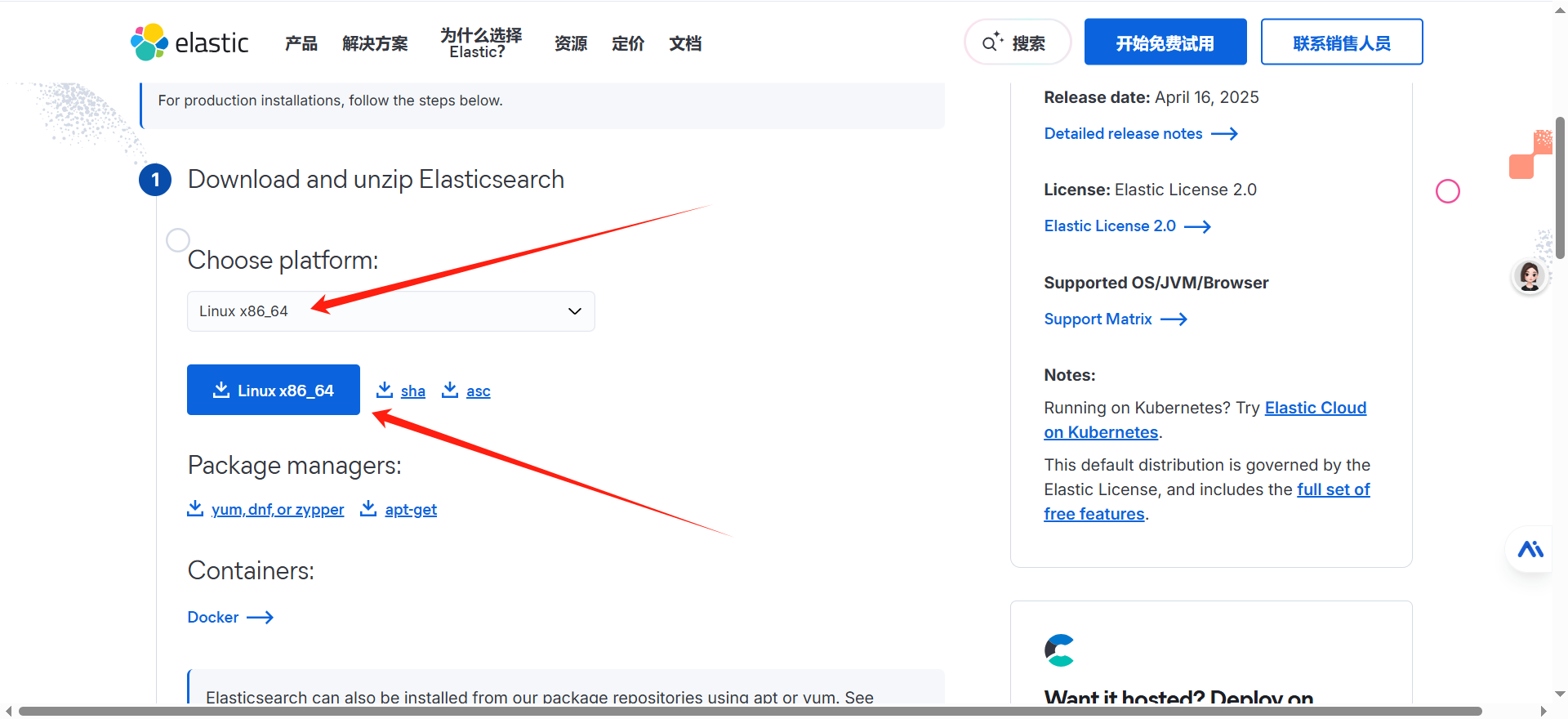
+**1、下载安装包**
+
+进入官网下载$linux$安装包 [下载地址](https://www.elastic.co/cn/downloads/elasticsearch)
+
+
+
+**2、安装$JDK$$21$**
+
+```sh
+sudo yum install java-21-openjdk-devel
+echo 'export JAVA_HOME=/usr/lib/jvm/java-21-openjdk
+export PATH=$JAVA_HOME/bin:$PATH' >> ~/.bashrc
+
+source ~/.bashrc
+```
+
+**3、上传文件到$linux$服务器**
+
+```sh
+# 如果没有 rz 命令 先安装
+yum -y install lrzsz
+
+# rz 打开弹窗 选择下载好的文件 确认 在哪个目录下执行,就会上传到该目录下
+rz -be
+```
+
+ **4、新建用户并设置密码**
+
+```sh
+# 创建用户
+useradd elauser
+
+# 设置密码 符合密码规范 大写 + 小写 + 数字 + 特殊字符 + 大于八位
+passwd elauser
+
+#输入密码:
+DsideaL@123
+
+tar -zxvf elasticsearch-9.0.2-linux-x86_64.tar.gz
+sudo chown -R elauser:elauser /usr/local/elasticsearch-9.0.2
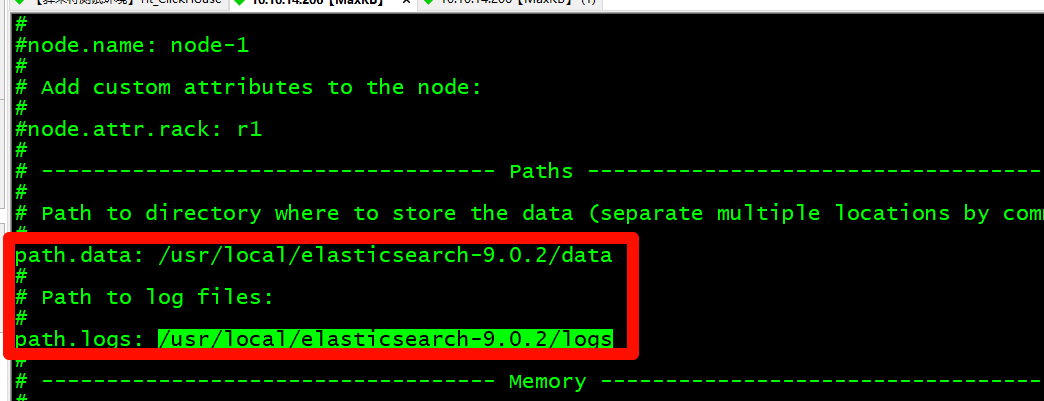
+# 进入解压文件并编辑配置文件
+cd elasticsearch-9.0.2/config
+vi elasticsearch.yml
+# 修改数据目录和日志目录
+mkdir -p /usr/local/elasticsearch-9.0.2/data
+mkdir -p /usr/local/elasticsearch-9.0.2/logs
+```
+
+
+
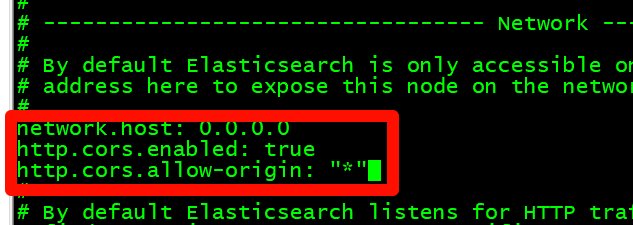
+设置允许所有IP进行访问,在添加下面参数让$elasticsearch-head$插件可以访问$es$
+
+
+
+```yaml
+network.host: 0.0.0.0
+http.cors.enabled: true
+http.cors.allow-origin: "*"
+```
+
+**5、修改系统配置**
+
+```sh
+# m.max_map_count 值太低
+# 临时解决方案(需要root权限)
+sudo sysctl -w vm.max_map_count=262144
+
+# 永久解决方案(需要root权限)
+echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
+sudo sysctl -p
+
+# 验证是否有效
+sysctl vm.max_map_count
+```
+
+**6、启动**
+
+```sh
+# 启动
+su - elauser
+
+cd /usr/local/elasticsearch-9.0.2/bin
+# ./elasticsearch-keystore create
+
+# 启动 -d = damon 守护进程
+./elasticsearch -d
+
+
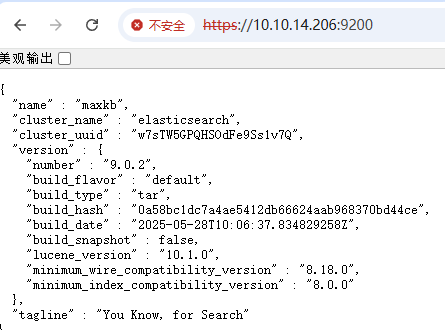
+# 访问地址
+https://10.10.14.206:9200
+
+# 日志文件
+/usr/local/elasticsearch-9.0.2/logs/elasticsearch.log
+```
+
+ 弹出输入账号密码,这里需要重置下密码,再登录 进入安装目录的bin目录下
+
+执行下面命令 就会在控制台打印出新密码 账号就是 elastic
+
+```
+./elasticsearch-reset-password -u elastic
+```
+
+
+
+登录成功,完活。
+
+```sh
+elastic
+jv9h8uwRrRxmDi1dq6u8
+```
+
+
+
+
+
+> **注意**:如果访问不到,请检查是否开启了$VPN$
+
+### 二、安装$ik$中文分词插件
+
+```bash
+# 安装分词插件
+./bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/9.0.2
+
+# 检查插件列表
+[elauser@maxkb elasticsearch-9.0.2]$ ./bin/elasticsearch-plugin list
+analysis-ik
+```
+
+
diff --git a/dsSchoolBuddy/ElasticSearch/T1_RebuildMapping.py b/dsSchoolBuddy/ElasticSearch/T1_RebuildMapping.py
new file mode 100644
index 00000000..0d5799bf
--- /dev/null
+++ b/dsSchoolBuddy/ElasticSearch/T1_RebuildMapping.py
@@ -0,0 +1,47 @@
+import warnings
+
+from elasticsearch import Elasticsearch
+
+from Config import Config
+
+# 抑制HTTPS相关警告
+warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
+warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
+
+# 初始化ES连接
+es = Elasticsearch(
+ hosts=Config.ES_CONFIG['hosts'],
+ basic_auth=Config.ES_CONFIG['basic_auth'],
+ verify_certs=False
+)
+
+# 定义mapping结构
+mapping = {
+ "mappings": {
+ "properties": {
+ "embedding": {
+ "type": "dense_vector",
+ "dims": 200, # embedding维度为200
+ "index": True,
+ "similarity": "l2_norm" # 使用L2距离
+ },
+ "user_input": {"type": "text"},
+ "tags": {
+ "type": "object",
+ "properties": {
+ "tags": {"type": "keyword"},
+ "full_content": {"type": "text"}
+ }
+ }
+ }
+ }
+}
+
+# 创建索引
+index_name = Config.ES_CONFIG['index_name']
+if es.indices.exists(index=index_name):
+ es.indices.delete(index=index_name)
+ print(f"删除已存在的索引 '{index_name}'")
+
+es.indices.create(index=index_name, body=mapping)
+print(f"索引 '{index_name}' 创建成功,mapping结构已设置。")
\ No newline at end of file
diff --git a/dsSchoolBuddy/ElasticSearch/T2_SplitTxt.py b/dsSchoolBuddy/ElasticSearch/T2_SplitTxt.py
new file mode 100644
index 00000000..7cfa4a61
--- /dev/null
+++ b/dsSchoolBuddy/ElasticSearch/T2_SplitTxt.py
@@ -0,0 +1,191 @@
+import os
+import re
+import shutil
+import warnings
+import zipfile
+
+from docx import Document
+from docx.oxml.ns import nsmap
+
+from Util import DocxUtil
+
+# 抑制HTTPS相关警告
+warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
+warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
+
+
+def extract_images_from_docx(docx_path, output_folder):
+ """
+ 从docx提取图片并记录位置
+ :param docx_path: Word文档路径
+ :param output_folder: 图片输出文件夹
+ :return: 包含图片路径和位置的列表
+ """
+ # 从docx_path 的名称示例:小学数学教学中的若干问题_MATH_1.docx
+ # 则图片的前缀统一为 MATH_1_?.docx ,其中 ? 为数字,表示图片的序号
+ # 先获取到前缀
+ a = docx_path.split("_")
+ prefix = a[1] + "_" + a[2].split(".")[0]
+ # print(f"图片前缀为:{prefix}")
+ # 创建一个List 记录每个图片的名称和序号
+ image_data = []
+ # 创建临时解压目录
+ temp_dir = os.path.join(output_folder, "temp_docx")
+ os.makedirs(temp_dir, exist_ok=True)
+
+ # 解压docx文件
+ with zipfile.ZipFile(docx_path, 'r') as zip_ref:
+ zip_ref.extractall(temp_dir)
+
+ # 读取主文档关系
+ with open(os.path.join(temp_dir, 'word', '_rels', 'document.xml.rels'), 'r') as rels_file:
+ rels_content = rels_file.read()
+
+ # 加载主文档
+ doc = Document(docx_path)
+ img_counter = 1
+
+ # 遍历所有段落
+ for para_idx, paragraph in enumerate(doc.paragraphs):
+ for run_idx, run in enumerate(paragraph.runs):
+ # 检查运行中的图形
+ for element in run._element:
+ if element.tag.endswith('drawing'):
+ # 提取图片关系ID
+ blip = element.find('.//a:blip', namespaces=nsmap)
+ if blip is not None:
+ embed_id = blip.get('{%s}embed' % nsmap['r'])
+
+ # 从关系文件中获取图片文件名
+ rel_entry = f' 2 else line
+ elif line and line[0].isdigit():
+ line = line[1:]
+ line = line.strip()
+ if in_block and line: # 只添加非空行
+ current_block.append(line)
+
+ if current_block:
+ blocks.append('\n'.join(current_block))
+
+ return [(i + 1, block) for i, block in enumerate(blocks)]
+
+
+def save_to_txt(content, file_path, mode='w'):
+ """将内容保存到文本文件"""
+ try:
+ with open(file_path, mode, encoding='utf-8') as f:
+ f.write(content)
+ return True
+ except Exception as e:
+ print(f"保存文件{file_path}时出错: {str(e)}")
+ return False
+
+
+class ImageReplacer:
+ def __init__(self, image_list):
+ self.image_list = image_list
+ self.current_idx = 0
+
+ def replace(self, match):
+ if self.current_idx < len(self.image_list):
+ result = f""
+ self.current_idx += 1
+ return result
+ return match.group()
+
+
+def process_document(docx_file, txt_output_dir, img_output_dir):
+ # 提取图片
+ listImage = extract_images_from_docx(docx_file, img_output_dir)
+ print(f"图片数量为:{len(listImage)}")
+
+ # 读取内容
+ res = DocxUtil.get_docx_content_by_pandoc(docx_file)
+ # 分块
+ chunks = split_into_blocks(res)
+ saved_count = 0
+
+ # 使用原来的正则表达式
+ pattern = re.compile(r'【图片\d+】')
+ # 创建图片替换器
+ replacer = ImageReplacer(listImage)
+
+ for x in chunks:
+ firstLine = x[1].split("\n")[0].strip()
+ content = x[1][len(firstLine):].strip()
+
+ # 使用类方法替换图片
+ content = pattern.sub(replacer.replace, content)
+ # 保存文本文件
+ # 从docx文件名提取学科和编号
+ docx_name = os.path.basename(docx_file).split('.')[0]
+ subject_part = '_'.join(docx_name.split('_')[-2:]) # 获取最后两部分如CHINESE_1
+ output_file = os.path.join(txt_output_dir, f"{subject_part}_{x[0]}.txt")
+ full_content = f"{firstLine}\n{content}"
+ if save_to_txt(full_content, output_file, mode='w'):
+ saved_count += 1
+
+ print(f"处理完成,共保存{saved_count}个文件到目录: {txt_output_dir}")
+
+
+if __name__ == "__main__":
+ txt_output_dir = "../Txt/"
+ img_output_dir = "../static/Images/"
+ # 清空上面的两个输出目录,用os进行删除,在Windows环境中进行
+ if os.path.exists(txt_output_dir):
+ shutil.rmtree(txt_output_dir)
+ if os.path.exists(img_output_dir):
+ shutil.rmtree(img_output_dir)
+ # 创建输出目录
+ os.makedirs(txt_output_dir, exist_ok=True)
+ os.makedirs(img_output_dir, exist_ok=True)
+
+ # 遍历static/Txt/下所有的docx
+ for filename in os.listdir("../static/Txt/"):
+ print("正在处理文件:" + filename)
+ # 这里需要文件的全称路径
+ filename = os.path.join("../static/Txt/", filename)
+ process_document(filename, txt_output_dir, img_output_dir)
diff --git a/dsSchoolBuddy/ElasticSearch/T3_InsertData.py b/dsSchoolBuddy/ElasticSearch/T3_InsertData.py
new file mode 100644
index 00000000..a2d8921b
--- /dev/null
+++ b/dsSchoolBuddy/ElasticSearch/T3_InsertData.py
@@ -0,0 +1,75 @@
+import warnings
+
+from Config import Config
+from Config.Config import *
+from elasticsearch import Elasticsearch
+from gensim.models import KeyedVectors
+import jieba
+import os
+import time
+
+# 抑制HTTPS相关警告
+warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
+warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
+
+# 1. 加载预训练的 Word2Vec 模型
+model_path = MODEL_PATH
+model = KeyedVectors.load_word2vec_format(model_path, binary=False, limit=MODEL_LIMIT)
+print(f"模型加载成功,词向量维度: {model.vector_size}")
+
+
+# 功能:将文本转换为嵌入向量
+def text_to_embedding(text):
+ words = jieba.lcut(text)
+ embeddings = [model[word] for word in words if word in model]
+ if embeddings:
+ return sum(embeddings) / len(embeddings)
+ return [0.0] * model.vector_size
+
+
+# 2. 初始化Elasticsearch连接
+es = Elasticsearch(
+ hosts=Config.ES_CONFIG['hosts'],
+ basic_auth=Config.ES_CONFIG['basic_auth'],
+ verify_certs=False
+)
+
+# 3. 处理processed_chunks目录下的所有文件
+txt_dir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), 'Txt')
+
+for filename in os.listdir(txt_dir):
+ if filename.endswith('.txt'):
+ filepath = os.path.join(txt_dir, filename)
+ with open(filepath, 'r', encoding='utf-8') as f:
+ # 只读取第一行作为向量计算
+ first_line = f.readline().strip()
+ # 读取全部内容用于后续查询
+ full_content = first_line + '\n' + f.read()
+
+ if not first_line:
+ print(f"跳过空文件: {filename}")
+ continue
+
+ print(f"正在处理文件: {filename}")
+
+ # 4. 获取当前时间和会话ID
+ timestamp = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
+ # 需要进行标记的标签
+ x = filename.split("_")
+ selectedTags = [x[0] + "_" + x[1]]
+ tags = {"tags": selectedTags, "full_content": full_content} # 添加完整内容
+
+ # 5. 将第一行文本转换为嵌入向量
+ embedding = text_to_embedding(first_line)
+
+ # 6. 插入数据到Elasticsearch
+ doc = {
+ 'tags': tags,
+ 'user_input': first_line,
+ 'timestamp': timestamp,
+ 'embedding': embedding
+ }
+ es.index(index=ES_CONFIG['index_name'], document=doc)
+ print(f"文件 {filename} 数据插入成功")
+
+print("所有文件处理完成")
diff --git a/dsSchoolBuddy/ElasticSearch/T4_SelectAllData.py b/dsSchoolBuddy/ElasticSearch/T4_SelectAllData.py
new file mode 100644
index 00000000..99418857
--- /dev/null
+++ b/dsSchoolBuddy/ElasticSearch/T4_SelectAllData.py
@@ -0,0 +1,55 @@
+import warnings
+
+from elasticsearch import Elasticsearch
+
+from Config import Config
+
+# 抑制HTTPS相关警告
+warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
+warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
+
+
+# 初始化Elasticsearch连接
+es = Elasticsearch(
+ hosts=Config.ES_CONFIG['hosts'],
+ basic_auth=Config.ES_CONFIG['basic_auth'],
+ verify_certs=False
+)
+
+# 查询所有数据
+def select_all_data(index_name):
+ try:
+ # 构建查询条件 - 匹配所有文档
+ # 修改查询条件为获取前10条数据
+ query = {
+ "query": {
+ "match_all": {}
+ },
+ "size": 1000 # 仅获取10条数据
+ }
+
+ # 执行查询
+ response = es.search(index=index_name, body=query)
+ hits = response['hits']['hits']
+
+ if not hits:
+ print(f"索引 {index_name} 中没有数据")
+ else:
+ print(f"索引 {index_name} 中共有 {len(hits)} 条数据:")
+ for i, hit in enumerate(hits, 1):
+ print(f"{i}. ID: {hit['_id']}")
+ print(f" 内容: {hit['_source'].get('user_input', '')}")
+ print(f" 标签: {hit['_source'].get('tags', '')}")
+ print(f" 时间戳: {hit['_source'].get('timestamp', '')}")
+ # 在循环中添加打印完整数据结构的代码
+ if i == 1: # 只打印第一条数据的完整结构
+ print("完整数据结构:")
+ import pprint
+ pp = pprint.PrettyPrinter(indent=4)
+ pp.pprint(hit['_source'])
+ print("-" * 50)
+ except Exception as e:
+ print(f"查询出错: {e}")
+
+if __name__ == "__main__":
+ select_all_data(Config.ES_CONFIG['index_name'])
\ No newline at end of file
diff --git a/dsSchoolBuddy/ElasticSearch/T5_SelectByTags.py b/dsSchoolBuddy/ElasticSearch/T5_SelectByTags.py
new file mode 100644
index 00000000..ae5e5d62
--- /dev/null
+++ b/dsSchoolBuddy/ElasticSearch/T5_SelectByTags.py
@@ -0,0 +1,79 @@
+from elasticsearch import Elasticsearch
+import warnings
+from Config import Config
+from Config.Config import ES_CONFIG
+import urllib3
+
+# 抑制HTTPS相关警告
+warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
+warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
+
+
+# 1. 初始化Elasticsearch连接
+es = Elasticsearch(
+ hosts=Config.ES_CONFIG['hosts'],
+ basic_auth=Config.ES_CONFIG['basic_auth'],
+ verify_certs=False
+)
+
+# 2. 直接在代码中指定要查询的标签
+query_tag = ["MATH_1"] # 可以修改为其他需要的标签
+
+# 3. 构建查询条件
+query = {
+ "query": {
+ "bool": {
+ "should": [
+ {
+ "terms": {
+ "tags.tags": query_tag
+ }
+ }
+ ],
+ "minimum_should_match": 1
+
+ }
+ },
+ "size": 1000
+}
+
+# 4. 执行查询并处理结果
+try:
+ response = es.search(index="knowledge_base", body=query)
+ hits = response['hits']['hits']
+
+ if not hits:
+ print(f"未找到标签为 '{query_tag}' 的数据。")
+ else:
+ print(f"找到 {len(hits)} 条标签为 '{query_tag}' 的数据:")
+ for i, hit in enumerate(hits, 1):
+ print(f"{i}. ID: {hit['_id']}")
+ print(f" 内容: {hit['_source'].get('user_input', '')}")
+ print(f" 标签: {hit['_source']['tags']['tags']}")
+ print("-" * 50)
+except Exception as e:
+ print(f"查询执行失败,错误详情: {str(e)}")
+ print(f"查询条件: {query}")
+ if hasattr(e, 'info') and isinstance(e.info, dict):
+ print(f"Elasticsearch错误详情: {e.info}")
+ if hasattr(e, 'status_code'):
+ print(f"HTTP状态码: {e.status_code}")
+ print(f"查询出错: {str(e)}")
+
+# 4. 执行查询
+try:
+ results = es.search(index=ES_CONFIG['index_name'], body=query)
+ print(f"查询标签 '{query_tag}' 结果:")
+ if results['hits']['hits']:
+ for hit in results['hits']['hits']:
+ doc = hit['_source']
+ print(f"ID: {hit['_id']}")
+ print(f"标签: {doc['tags']['tags']}")
+ print(f"用户问题: {doc['user_input']}")
+ print(f"时间: {doc['timestamp']}")
+ print(f"向量: {doc['embedding'][:5]}...")
+ print("-" * 40)
+ else:
+ print(f"未找到标签为 '{query_tag}' 的数据。")
+except Exception as e:
+ print(f"查询失败: {e}")
\ No newline at end of file
diff --git a/dsSchoolBuddy/ElasticSearch/T6_XiangLiangQuery.py b/dsSchoolBuddy/ElasticSearch/T6_XiangLiangQuery.py
new file mode 100644
index 00000000..215ab7ad
--- /dev/null
+++ b/dsSchoolBuddy/ElasticSearch/T6_XiangLiangQuery.py
@@ -0,0 +1,109 @@
+import logging
+import warnings
+
+from Config.Config import ES_CONFIG
+from Util.EsSearchUtil import EsSearchUtil
+
+# 初始化日志
+logger = logging.getLogger(__name__)
+logger.setLevel(logging.INFO)
+
+# 初始化EsSearchUtil
+esClient = EsSearchUtil(ES_CONFIG)
+# 抑制HTTPS相关警告
+warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
+warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
+
+if __name__ == "__main__":
+ # 测试查询
+ # query = "小学数学中有哪些模型"
+ query = "文言虚词"
+ query_tags = ["MATH_1"] # 默认搜索标签,可修改
+ print(f"\n=== 开始执行查询 ===")
+ print(f"原始查询文本: {query}")
+
+ # 执行混合搜索
+ es_conn = esClient.es_pool.get_connection()
+ try:
+ # 向量搜索
+ print("\n=== 向量搜索阶段 ===")
+ print("1. 文本分词和向量化处理中...")
+ query_embedding = esClient.text_to_embedding(query)
+ print(f"2. 生成的查询向量维度: {len(query_embedding)}")
+ print(f"3. 前3维向量值: {query_embedding[:3]}")
+
+ print("4. 正在执行Elasticsearch向量搜索...")
+ vector_results = es_conn.search(
+ index=ES_CONFIG['index_name'],
+ body={
+ "query": {
+ "script_score": {
+ "query": {
+ "bool": {
+ "should": [
+ {
+ "terms": {
+ "tags.tags": query_tags
+ }
+ }
+ ],
+ "minimum_should_match": 1
+ }
+ },
+ "script": {
+ "source": "double score = cosineSimilarity(params.query_vector, 'embedding'); return score >= 0 ? score : 0",
+ "params": {"query_vector": query_embedding}
+ }
+ }
+ },
+ "size": 3
+ }
+ )
+ print(f"5. 向量搜索结果数量: {len(vector_results['hits']['hits'])}")
+
+ # 文本精确搜索
+ print("\n=== 文本精确搜索阶段 ===")
+ print("1. 正在执行Elasticsearch文本精确搜索...")
+ text_results = es_conn.search(
+ index=ES_CONFIG['index_name'],
+ body={
+ "query": {
+ "bool": {
+ "must": [
+ {
+ "match": {
+ "user_input": query
+ }
+ },
+ {
+ "terms": {
+ "tags.tags": query_tags
+ }
+ }
+ ]
+ }
+ },
+ "size": 3
+ }
+ )
+ print(f"2. 文本搜索结果数量: {len(text_results['hits']['hits'])}")
+
+ # 打印详细结果
+ print("\n=== 最终搜索结果 ===")
+
+ vector_int = 0
+ for i, hit in enumerate(vector_results['hits']['hits'], 1):
+ if hit['_score'] > 0.4: # 阀值0.4
+ print(f" {i}. 文档ID: {hit['_id']}, 相似度分数: {hit['_score']:.2f}")
+ print(f" 内容: {hit['_source']['user_input']}")
+ vector_int = vector_int + 1
+ print(f" 向量搜索结果: {vector_int}条")
+
+ print("\n文本精确搜索结果:")
+ for i, hit in enumerate(text_results['hits']['hits']):
+ print(f" {i + 1}. 文档ID: {hit['_id']}, 匹配分数: {hit['_score']:.2f}")
+ print(f" 内容: {hit['_source']['user_input']}")
+ # print(f" 详细: {hit['_source']['tags']['full_content']}")
+
+ finally:
+ esClient.es_pool.release_connection(es_conn)
diff --git a/dsSchoolBuddy/ElasticSearch/Utils/ElasticsearchCollectionManager.py b/dsSchoolBuddy/ElasticSearch/Utils/ElasticsearchCollectionManager.py
new file mode 100644
index 00000000..4db6a138
--- /dev/null
+++ b/dsSchoolBuddy/ElasticSearch/Utils/ElasticsearchCollectionManager.py
@@ -0,0 +1,111 @@
+from elasticsearch import Elasticsearch
+from elasticsearch.exceptions import NotFoundError
+import logging
+
+logger = logging.getLogger(__name__)
+
+
+class ElasticsearchCollectionManager:
+ def __init__(self, index_name):
+ """
+ 初始化Elasticsearch索引管理器
+ :param index_name: Elasticsearch索引名称
+ """
+ self.index_name = index_name
+
+ def load_collection(self, es_connection):
+ """
+ 加载索引,如果不存在则创建
+ :param es_connection: Elasticsearch连接
+ """
+ try:
+ if not es_connection.indices.exists(index=self.index_name):
+ logger.warning(f"Index {self.index_name} does not exist, creating new index")
+ self._create_index(es_connection)
+ except Exception as e:
+ logger.error(f"Failed to load collection: {str(e)}")
+ raise
+
+ def _create_index(self, es_connection):
+ """创建新的Elasticsearch索引"""
+ mapping = {
+ "mappings": {
+ "properties": {
+ "user_input": {"type": "text"},
+ "tags": {
+ "type": "object",
+ "properties": {
+ "tags": {"type": "keyword"},
+ "full_content": {"type": "text"}
+ }
+ },
+ "timestamp": {"type": "date"},
+ "embedding": {"type": "dense_vector", "dims": 200}
+ }
+ }
+ }
+ es_connection.indices.create(index=self.index_name, body=mapping)
+
+ def search(self, es_connection, query_embedding, search_params, expr=None, limit=5):
+ """
+ 执行混合搜索(向量+关键字)
+ :param es_connection: Elasticsearch连接
+ :param query_embedding: 查询向量
+ :param search_params: 搜索参数
+ :param expr: 过滤表达式
+ :param limit: 返回结果数量
+ :return: 搜索结果
+ """
+ try:
+ # 构建查询
+ query = {
+ "query": {
+ "script_score": {
+ "query": {
+ "bool": {
+ "must": []
+ }
+ },
+ "script": {
+ "source": "cosineSimilarity(params.query_vector, 'embedding') + 1.0",
+ "params": {"query_vector": query_embedding}
+ }
+ }
+ },
+ "size": limit
+ }
+
+ # 添加标签过滤条件
+ if expr:
+ query["query"]["script_score"]["query"]["bool"]["must"].append(
+ {"nested": {
+ "path": "tags",
+ "query": {
+ "terms": {"tags.tags": expr.split(" OR ")}
+ }
+ }}
+ )
+
+ logger.info(f"Executing search with query: {query}")
+ response = es_connection.search(index=self.index_name, body=query)
+ return response["hits"]["hits"]
+ except Exception as e:
+ logger.error(f"Search failed: {str(e)}")
+ raise
+
+ def query_by_id(self, es_connection, doc_id):
+ """
+ 根据ID查询文档
+ :param es_connection: Elasticsearch连接
+ :param doc_id: 文档ID
+ :return: 文档内容
+ """
+ try:
+ response = es_connection.get(index=self.index_name, id=doc_id)
+ return response["_source"]
+ except NotFoundError:
+ logger.warning(f"Document with id {doc_id} not found")
+ return None
+ except Exception as e:
+ logger.error(f"Failed to query document by id: {str(e)}")
+ raise
\ No newline at end of file
diff --git a/dsSchoolBuddy/ElasticSearch/Utils/ElasticsearchConnectionPool.py b/dsSchoolBuddy/ElasticSearch/Utils/ElasticsearchConnectionPool.py
new file mode 100644
index 00000000..88a877fc
--- /dev/null
+++ b/dsSchoolBuddy/ElasticSearch/Utils/ElasticsearchConnectionPool.py
@@ -0,0 +1,65 @@
+from elasticsearch import Elasticsearch
+import threading
+import logging
+
+logger = logging.getLogger(__name__)
+
+
+class ElasticsearchConnectionPool:
+ def __init__(self, hosts, basic_auth, verify_certs=False, max_connections=50):
+ """
+ 初始化Elasticsearch连接池
+ :param hosts: Elasticsearch服务器地址
+ :param basic_auth: 认证信息(username, password)
+ :param verify_certs: 是否验证SSL证书
+ :param max_connections: 最大连接数
+ """
+ self.hosts = hosts
+ self.basic_auth = basic_auth
+ self.verify_certs = verify_certs
+ self.max_connections = max_connections
+ self._connections = []
+ self._lock = threading.Lock()
+ self._initialize_pool()
+
+ def _initialize_pool(self):
+ """初始化连接池"""
+ for _ in range(self.max_connections):
+ self._connections.append(self._create_connection())
+
+ def _create_connection(self):
+ """创建新的Elasticsearch连接"""
+ return Elasticsearch(
+ hosts=self.hosts,
+ basic_auth=self.basic_auth,
+ verify_certs=self.verify_certs
+ )
+
+ def get_connection(self):
+ """从连接池获取一个连接"""
+ with self._lock:
+ if not self._connections:
+ logger.warning("Connection pool exhausted, creating new connection")
+ return self._create_connection()
+ return self._connections.pop()
+
+ def release_connection(self, connection):
+ """释放连接回连接池"""
+ with self._lock:
+ if len(self._connections) < self.max_connections:
+ self._connections.append(connection)
+ else:
+ try:
+ connection.close()
+ except Exception as e:
+ logger.warning(f"Failed to close connection: {str(e)}")
+
+ def close(self):
+ """关闭所有连接"""
+ with self._lock:
+ for conn in self._connections:
+ try:
+ conn.close()
+ except Exception as e:
+ logger.warning(f"Failed to close connection: {str(e)}")
+ self._connections.clear()
\ No newline at end of file
diff --git a/dsSchoolBuddy/ElasticSearch/Utils/__pycache__/ElasticsearchCollectionManager.cpython-310.pyc b/dsSchoolBuddy/ElasticSearch/Utils/__pycache__/ElasticsearchCollectionManager.cpython-310.pyc
new file mode 100644
index 00000000..05971151
Binary files /dev/null and b/dsSchoolBuddy/ElasticSearch/Utils/__pycache__/ElasticsearchCollectionManager.cpython-310.pyc differ
diff --git a/dsSchoolBuddy/ElasticSearch/Utils/__pycache__/ElasticsearchConnectionPool.cpython-310.pyc b/dsSchoolBuddy/ElasticSearch/Utils/__pycache__/ElasticsearchConnectionPool.cpython-310.pyc
new file mode 100644
index 00000000..2c77d6cb
Binary files /dev/null and b/dsSchoolBuddy/ElasticSearch/Utils/__pycache__/ElasticsearchConnectionPool.cpython-310.pyc differ
diff --git a/dsSchoolBuddy/ElasticSearch/__init__.py b/dsSchoolBuddy/ElasticSearch/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/dsSchoolBuddy/ElasticSearch/__pycache__/__init__.cpython-310.pyc b/dsSchoolBuddy/ElasticSearch/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 00000000..94ae6ce2
Binary files /dev/null and b/dsSchoolBuddy/ElasticSearch/__pycache__/__init__.cpython-310.pyc differ
diff --git a/dsSchoolBuddy/Start.py b/dsSchoolBuddy/Start.py
new file mode 100644
index 00000000..239a94c3
--- /dev/null
+++ b/dsSchoolBuddy/Start.py
@@ -0,0 +1,171 @@
+import json
+import subprocess
+import tempfile
+import urllib.parse
+import uuid
+import warnings
+from io import BytesIO
+
+import fastapi
+import uvicorn
+from fastapi import FastAPI, HTTPException
+from openai import AsyncOpenAI
+from sse_starlette import EventSourceResponse
+from starlette.responses import StreamingResponse
+from starlette.staticfiles import StaticFiles
+
+from Config import Config
+from Util.EsSearchUtil import *
+from Util.MySQLUtil import init_mysql_pool
+
+# 初始化日志
+logger = logging.getLogger(__name__)
+logger.setLevel(logging.INFO)
+
+# 配置日志处理器
+log_file = os.path.join(os.path.dirname(__file__), 'Logs', 'app.log')
+os.makedirs(os.path.dirname(log_file), exist_ok=True)
+
+# 文件处理器
+file_handler = RotatingFileHandler(
+ log_file, maxBytes=1024 * 1024, backupCount=5, encoding='utf-8')
+file_handler.setFormatter(logging.Formatter(
+ '%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
+
+# 控制台处理器
+console_handler = logging.StreamHandler()
+console_handler.setFormatter(logging.Formatter(
+ '%(asctime)s - %(name)s - %(levelname)s - %(message)s'))
+
+logger.addHandler(file_handler)
+logger.addHandler(console_handler)
+
+# 初始化异步 OpenAI 客户端
+client = AsyncOpenAI(
+ api_key=Config.MODEL_API_KEY,
+ base_url=Config.MODEL_API_URL,
+)
+
+
+async def lifespan(app: FastAPI):
+ # 抑制HTTPS相关警告
+ warnings.filterwarnings('ignore', message='Connecting to .* using TLS with verify_certs=False is insecure')
+ warnings.filterwarnings('ignore', message='Unverified HTTPS request is being made to host')
+ yield
+
+
+app = FastAPI(lifespan=lifespan)
+
+# 挂载静态文件目录
+app.mount("/static", StaticFiles(directory="Static"), name="static")
+
+
+@app.post("/api/save-word")
+async def save_to_word(request: fastapi.Request):
+ output_file = None
+ try:
+ # Parse request data
+ try:
+ data = await request.json()
+ markdown_content = data.get('markdown_content', '')
+ if not markdown_content:
+ raise ValueError("Empty MarkDown content")
+ except Exception as e:
+ logger.error(f"Request parsing failed: {str(e)}")
+ raise HTTPException(status_code=400, detail=f"Invalid request: {str(e)}")
+
+ # 创建临时Markdown文件
+ temp_md = os.path.join(tempfile.gettempdir(), uuid.uuid4().hex + ".md")
+ with open(temp_md, "w", encoding="utf-8") as f:
+ f.write(markdown_content)
+
+ # 使用pandoc转换
+ output_file = os.path.join(tempfile.gettempdir(), "【理想大模型】问答.docx")
+ subprocess.run(['pandoc', temp_md, '-o', output_file, '--resource-path=static'], check=True)
+
+ # 读取生成的Word文件
+ with open(output_file, "rb") as f:
+ stream = BytesIO(f.read())
+
+ # 返回响应
+ encoded_filename = urllib.parse.quote("【理想大模型】问答.docx")
+ return StreamingResponse(
+ stream,
+ media_type="application/vnd.openxmlformats-officedocument.wordprocessingml.document",
+ headers={"Content-Disposition": f"attachment; filename*=UTF-8''{encoded_filename}"})
+
+ except HTTPException:
+ raise
+ except Exception as e:
+ logger.error(f"Unexpected error: {str(e)}")
+ raise HTTPException(status_code=500, detail="Internal server error")
+ finally:
+ # 清理临时文件
+ try:
+ if temp_md and os.path.exists(temp_md):
+ os.remove(temp_md)
+ if output_file and os.path.exists(output_file):
+ os.remove(output_file)
+ except Exception as e:
+ logger.warning(f"Failed to clean up temp files: {str(e)}")
+
+
+@app.post("/api/rag", response_model=None)
+async def rag(request: fastapi.Request):
+ data = await request.json()
+ query = data.get('query', '')
+ query_tags = data.get('tags', [])
+ # 调用es进行混合搜索
+ search_results = EsSearchUtil.queryByEs(query, query_tags, logger)
+ # 构建提示词
+ context = "\n".join([
+ f"结果{i + 1}: {res['tags']['full_content']}"
+ for i, res in enumerate(search_results['text_results'])
+ ])
+ # 添加图片识别提示
+ prompt = f"""
+ 信息检索与回答助手
+ 根据以下关于'{query}'的相关信息:
+
+ 相关信息
+ {context}
+
+ 回答要求
+ 1. 对于公式内容:
+ - 使用行内格式:$公式$
+ - 重要公式可单独一行显示
+ - 绝对不要使用代码块格式(```或''')
+ - 可适当使用\large增大公式字号
+ - 如果内容中包含数学公式,请使用行内格式,如$f(x) = x^2$
+ - 如果内容中包含多个公式,请使用行内格式,如$f(x) = x^2$ $g(x) = x^3$
+ 2. 如果没有提供任何资料,那就直接拒绝回答,明确不在知识范围内。
+ 3. 如果发现提供的资料与要询问的问题都不相关,就拒绝回答,明确不在知识范围内。
+ 4. 如果发现提供的资料中只有部分与问题相符,那就只提取有用的相关部分,其它部分请忽略。
+ 5. 对于符合问题的材料中,提供了图片的,尽量保持上下文中的图片,并尽量保持图片的清晰度。
+ """
+
+ async def generate_response_stream():
+ try:
+ # 流式调用大模型
+ stream = await client.chat.completions.create(
+ model=Config.MODEL_NAME,
+ messages=[
+ {'role': 'user', 'content': prompt}
+ ],
+ max_tokens=8000,
+ stream=True # 启用流式模式
+ )
+ # 流式返回模型生成的回复
+ async for chunk in stream:
+ if chunk.choices[0].delta.content:
+ yield f"data: {json.dumps({'reply': chunk.choices[0].delta.content}, ensure_ascii=False)}\n\n"
+
+ except Exception as e:
+ yield f"data: {json.dumps({'error': str(e)})}\n\n"
+
+ return EventSourceResponse(generate_response_stream())
+
+
+
+if __name__ == "__main__":
+ uvicorn.run(app, host="0.0.0.0", port=8000)
diff --git a/dsSchoolBuddy/Test/__init__.py b/dsSchoolBuddy/Test/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/dsSchoolBuddy/Util/EsSearchUtil.py b/dsSchoolBuddy/Util/EsSearchUtil.py
new file mode 100644
index 00000000..a9a2e7ec
--- /dev/null
+++ b/dsSchoolBuddy/Util/EsSearchUtil.py
@@ -0,0 +1,238 @@
+import logging
+import os
+from logging.handlers import RotatingFileHandler
+import jieba
+from gensim.models import KeyedVectors
+
+from Config.Config import MODEL_LIMIT, MODEL_PATH, ES_CONFIG
+from ElasticSearch.Utils.ElasticsearchConnectionPool import ElasticsearchConnectionPool
+
+# 初始化日志
+logger = logging.getLogger(__name__)
+logger.setLevel(logging.INFO)
+# 确保日志目录存在
+os.makedirs('Logs', exist_ok=True)
+handler = RotatingFileHandler('Logs/start.log', maxBytes=1024 * 1024, backupCount=5)
+handler.setFormatter(logging.Formatter('%(asctime)s - %(levelname)s - %(message)s'))
+logger.addHandler(handler)
+
+class EsSearchUtil:
+ def __init__(self, es_config):
+ """
+ 初始化Elasticsearch搜索工具
+ :param es_config: Elasticsearch配置字典,包含hosts, username, password, index_name等
+ """
+ self.es_config = es_config
+
+ # 初始化连接池
+ self.es_pool = ElasticsearchConnectionPool(
+ hosts=es_config['hosts'],
+ basic_auth=es_config['basic_auth'],
+ verify_certs=es_config.get('verify_certs', False),
+ max_connections=50
+ )
+
+ # 保留直接连接用于兼容
+ from elasticsearch import Elasticsearch
+ self.es = Elasticsearch(
+ hosts=es_config['hosts'],
+ basic_auth=es_config['basic_auth'],
+ verify_certs=es_config.get('verify_certs', False)
+ )
+
+ # 确保es_conn属性存在以兼容旧代码
+ self.es_conn = self.es
+
+ # 确保es_conn属性存在以兼容旧代码
+ self.es_conn = self.es
+
+
+ # 加载预训练模型
+ self.model = KeyedVectors.load_word2vec_format(MODEL_PATH, binary=False, limit=MODEL_LIMIT)
+ logger.info(f"模型加载成功,词向量维度: {self.model.vector_size}")
+
+ # 初始化Elasticsearch连接
+ self.es = Elasticsearch(
+ hosts=es_config['hosts'],
+ basic_auth=es_config['basic_auth'],
+ verify_certs=False
+ )
+ self.index_name = es_config['index_name']
+
+ def text_to_embedding(self, text):
+ # 使用已加载的模型
+ # 对文本分词并计算平均向量
+ words = jieba.lcut(text)
+ vectors = [self.model[word] for word in words if word in self.model]
+
+ if not vectors:
+ return [0.0] * self.model.vector_size
+
+ # 计算平均向量
+ avg_vector = [sum(dim)/len(vectors) for dim in zip(*vectors)]
+ return avg_vector
+
+ def vector_search(self, query, size=10):
+ query_embedding = self.text_to_embedding(query)
+ script_query = {
+ "script_score": {
+ "query": {"match_all": {}},
+ "script": {
+ "source": "double score = cosineSimilarity(params.query_vector, 'embedding'); return score >= 0 ? score : 0",
+ "params": {"query_vector": query_embedding}
+ }
+ }
+ }
+
+ return self.es_conn.search(
+ index=self.es_config['index_name'],
+ query=script_query,
+ size=size
+ )
+
+ def text_search(self, query, size=10):
+ return self.es_conn.search(
+ index=self.es_config['index_name'],
+ query={"match": {"user_input": query}},
+ size=size
+ )
+
+ def hybrid_search(self, query, size=10):
+ """
+ 执行混合搜索(向量搜索+文本搜索)
+ :param query: 搜索查询文本
+ :param size: 返回结果数量
+ :return: 包含两种搜索结果的字典
+ """
+ vector_results = self.vector_search(query, size)
+ text_results = self.text_search(query, size)
+
+ return {
+ 'vector_results': vector_results,
+ 'text_results': text_results
+ }
+
+ def search(self, query, search_type='hybrid', size=10):
+ """
+ 统一搜索接口
+ :param query: 搜索查询文本
+ :param search_type: 搜索类型('vector', 'text' 或 'hybrid')
+ :param size: 返回结果数量
+ :return: 搜索结果
+ """
+ if search_type == 'vector':
+ return self.vector_search(query, size)
+ elif search_type == 'text':
+ return self.text_search(query, size)
+ else:
+ return self.hybrid_search(query, size)
+
+ def queryByEs(query, query_tags, logger):
+ # 获取EsSearchUtil实例
+ es_search_util = EsSearchUtil(ES_CONFIG)
+
+ # 执行混合搜索
+ es_conn = es_search_util.es_pool.get_connection()
+ try:
+ # 向量搜索
+ logger.info(f"\n=== 开始执行查询 ===")
+ logger.info(f"原始查询文本: {query}")
+ logger.info(f"查询标签: {query_tags}")
+
+ logger.info("\n=== 向量搜索阶段 ===")
+ logger.info("1. 文本分词和向量化处理中...")
+ query_embedding = es_search_util.text_to_embedding(query)
+ logger.info(f"2. 生成的查询向量维度: {len(query_embedding)}")
+ logger.info(f"3. 前3维向量值: {query_embedding[:3]}")
+
+ logger.info("4. 正在执行Elasticsearch向量搜索...")
+ vector_results = es_conn.search(
+ index=ES_CONFIG['index_name'],
+ body={
+ "query": {
+ "script_score": {
+ "query": {
+ "bool": {
+ "should": [
+ {
+ "terms": {
+ "tags.tags": query_tags
+ }
+ }
+ ],
+ "minimum_should_match": 1
+ }
+ },
+ "script": {
+ "source": "double score = cosineSimilarity(params.query_vector, 'embedding'); return score >= 0 ? score : 0",
+ "params": {"query_vector": query_embedding}
+ }
+ }
+ },
+ "size": 3
+ }
+ )
+ # 处理一下,判断是否到达阀值
+ filtered_vector_hits = []
+ vector_int = 0
+ for hit in vector_results['hits']['hits']:
+ if hit['_score'] > 0.8: # 阀值0.8
+ # 新增语义相关性检查
+ if all(word in hit['_source']['user_input'] for word in jieba.lcut(query)):
+ logger.info(f" {vector_int + 1}. 文档ID: {hit['_id']}, 相似度分数: {hit['_score']:.2f}")
+ logger.info(f" 内容: {hit['_source']['user_input']}")
+ filtered_vector_hits.append(hit)
+ vector_int += 1
+
+ # 更新vector_results只包含通过过滤的文档
+ vector_results['hits']['hits'] = filtered_vector_hits
+ logger.info(f"5. 向量搜索结果数量(过滤后): {vector_int}")
+
+ # 文本精确搜索
+ logger.info("\n=== 文本精确搜索阶段 ===")
+ logger.info("1. 正在执行Elasticsearch文本精确搜索...")
+ text_results = es_conn.search(
+ index=ES_CONFIG['index_name'],
+ body={
+ "query": {
+ "bool": {
+ "must": [
+ {
+ "match": {
+ "user_input": query
+ }
+ },
+ {
+ "terms": {
+ "tags.tags": query_tags
+ }
+ }
+ ]
+ }
+ },
+ "size": 3
+ }
+ )
+ logger.info(f"2. 文本搜索结果数量: {len(text_results['hits']['hits'])}")
+
+ # 合并vector和text结果
+ all_sources = [hit['_source'] for hit in vector_results['hits']['hits']] + \
+ [hit['_source'] for hit in text_results['hits']['hits']]
+
+ # 去重处理
+ unique_sources = []
+ seen_user_inputs = set()
+
+ for source in all_sources:
+ if source['user_input'] not in seen_user_inputs:
+ seen_user_inputs.add(source['user_input'])
+ unique_sources.append(source)
+
+ logger.info(f"合并后去重结果数量: {len(unique_sources)}条")
+
+ search_results = {
+ "text_results": unique_sources
+ }
+ return search_results
+ finally:
+ es_search_util.es_pool.release_connection(es_conn)
\ No newline at end of file
diff --git a/dsSchoolBuddy/Util/__init__.py b/dsSchoolBuddy/Util/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/dsSchoolBuddy/Util/__pycache__/ALiYunUtil.cpython-310.pyc b/dsSchoolBuddy/Util/__pycache__/ALiYunUtil.cpython-310.pyc
new file mode 100644
index 00000000..b26f07ed
Binary files /dev/null and b/dsSchoolBuddy/Util/__pycache__/ALiYunUtil.cpython-310.pyc differ
diff --git a/dsSchoolBuddy/Util/__pycache__/EsSearchUtil.cpython-310.pyc b/dsSchoolBuddy/Util/__pycache__/EsSearchUtil.cpython-310.pyc
new file mode 100644
index 00000000..e7e38fcb
Binary files /dev/null and b/dsSchoolBuddy/Util/__pycache__/EsSearchUtil.cpython-310.pyc differ
diff --git a/dsSchoolBuddy/Util/__pycache__/SearchUtil.cpython-310.pyc b/dsSchoolBuddy/Util/__pycache__/SearchUtil.cpython-310.pyc
new file mode 100644
index 00000000..ab6219cd
Binary files /dev/null and b/dsSchoolBuddy/Util/__pycache__/SearchUtil.cpython-310.pyc differ
diff --git a/dsSchoolBuddy/Util/__pycache__/__init__.cpython-310.pyc b/dsSchoolBuddy/Util/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 00000000..79767003
Binary files /dev/null and b/dsSchoolBuddy/Util/__pycache__/__init__.cpython-310.pyc differ